Tìm hiểu Directional Stimulus Prompting - Phương pháp trong việc hướng dẫn mô hình ngôn ngữ lớn
Directional Stimulus Prompting (DSP) là một phương pháp đột phá giúp điều hướng các mô hình ngôn ngữ lớn (LLM) tạo ra kết quả mong muốn mà không cần truy cập vào cấu trúc bên trong của chúng, mở ra khả năng tùy chỉnh hiệu quả cho các ứng dụng AI ngôn ngữ hiện đại.
1. Giới thiệu về Directional Stimulus Prompting
Directional Stimulus Prompting (DSP) là một Framework được giới thiệu bởi Li và cộng sự trong bài báo nghiên cứu được công bố tại hội nghị NeurIPS 2023. Phương pháp này được thiết kế để hướng dẫn các mô hình ngôn ngữ lớn (LLM) tạo ra kết quả mong muốn mà không cần truy cập trực tiếp vào cấu trúc bên trong của chúng.
Trong bối cảnh các mô hình ngôn ngữ lớn như GPT, LLaMA, và các mô hình tương tự ngày càng phổ biến, việc điều chỉnh chúng để đáp ứng nhu cầu cụ thể gặp nhiều thách thức. Đặc biệt khi các mô hình này thường được cung cấp dưới dạng "hộp đen" (black-box), nghĩa là người dùng không thể truy cập vào cấu trúc bên trong hoặc tham số của chúng. DSP ra đời như một giải pháp khắc phục hạn chế này.
2. Nguyên lý hoạt động của DSP
2.1. Cơ chế cơ bản
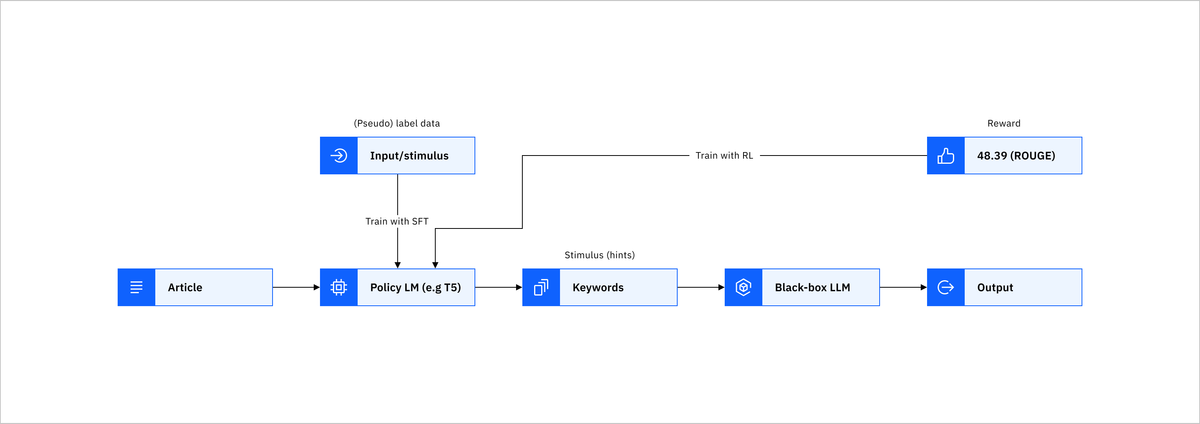
Thay vì điều chỉnh trực tiếp các tham số của LLM, DSP sử dụng một mô hình ngôn ngữ nhỏ hơn, có thể điều chỉnh được (ví dụ: T5) để tạo ra một "kích thích định hướng" (directional stimulus) cho mỗi đầu vào. Kích thích này đóng vai trò như một gợi ý hoặc manh mối giúp LLM tạo ra kết quả mong muốn.
Quy trình hoạt động của DSP bao gồm các bước sau:
- Đầu vào ban đầu: Hệ thống nhận một đầu vào cần xử lý.
- Tạo kích thích định hướng: Mô hình chính sách (policy model) được huấn luyện sẽ tạo ra một kích thích định hướng phù hợp với đầu vào.
- Kết hợp với đầu vào: Kích thích định hướng được kết hợp với đầu vào ban đầu.
- Xử lý bởi LLM: Đầu vào đã được tăng cường được đưa vào LLM để tạo ra kết quả cuối cùng.
2.2. Mô hình chính sách (Policy Model)
Mô hình chính sách đóng vai trò quan trọng trong DSP. Đây là một mô hình ngôn ngữ nhỏ hơn (như T5) được huấn luyện đặc biệt để tạo ra các kích thích định hướng phù hợp. Mô hình này học cách tạo ra các gợi ý hoặc manh mối có thể dẫn dắt LLM tạo ra kết quả mong muốn.
Quá trình huấn luyện mô hình chính sách sử dụng phương pháp học tăng cường (reinforcement learning), trong đó phản hồi từ LLM được sử dụng để điều chỉnh mô hình chính sách. Mục tiêu là tối ưu hóa khả năng của mô hình chính sách trong việc tạo ra các kích thích định hướng hiệu quả.
3. Ứng dụng của DSP
DSP có thể được áp dụng trong nhiều tác vụ xử lý ngôn ngữ tự nhiên, bao gồm:
3.1. Tóm tắt văn bản
Trong tác vụ tóm tắt văn bản, DSP có thể được sử dụng để hướng dẫn LLM tạo ra các bản tóm tắt có chất lượng cao hơn. Mô hình chính sách tạo ra các từ khóa hoặc cụm từ quan trọng từ văn bản gốc, giúp LLM tập trung vào những thông tin quan trọng khi tạo bản tóm tắt.
Ví dụ, khi cần tóm tắt một bài báo khoa học, mô hình chính sách có thể tạo ra các từ khóa như "phương pháp mới", "kết quả thí nghiệm", "ứng dụng tiềm năng", giúp LLM tạo ra bản tóm tắt bao gồm các thông tin quan trọng này.
3.2. Tạo văn bản theo chủ đề
DSP cũng hiệu quả trong việc hướng dẫn LLM tạo ra văn bản theo chủ đề cụ thể. Mô hình chính sách tạo ra các gợi ý liên quan đến chủ đề, giúp LLM tạo ra nội dung phù hợp và tập trung.
Ví dụ, khi cần tạo một bài viết về biến đổi khí hậu, mô hình chính sách có thể tạo ra các gợi ý như "hiệu ứng nhà kính", "nhiệt độ toàn cầu tăng", "giải pháp bền vững", giúp LLM tạo ra nội dung liên quan đến các khía cạnh này của vấn đề.
3.3. Điều chỉnh phong cách viết
DSP có thể được sử dụng để điều chỉnh phong cách viết của LLM. Mô hình chính sách tạo ra các gợi ý liên quan đến phong cách mong muốn, giúp LLM tạo ra văn bản với phong cách phù hợp.
Ví dụ, khi cần tạo một bài viết với phong cách học thuật, mô hình chính sách có thể tạo ra các gợi ý như "phân tích khách quan", "dẫn chứng nghiên cứu", "lập luận logic", giúp LLM tạo ra văn bản với phong cách học thuật.
4. Ưu điểm của DSP so với các phương pháp khác
4.1. Không cần truy cập vào cấu trúc bên trong của LLM
Một trong những ưu điểm lớn nhất của DSP là khả năng hướng dẫn LLM mà không cần truy cập vào cấu trúc bên trong hoặc tham số của chúng. Điều này đặc biệt hữu ích khi làm việc với các mô hình "hộp đen" như GPT-3, GPT-4, hoặc các mô hình thương mại khác.
4.2. Hiệu quả về mặt tài nguyên
So với việc tinh chỉnh toàn bộ LLM, DSP hiệu quả hơn về mặt tài nguyên tính toán. Chỉ cần huấn luyện một mô hình nhỏ hơn (mô hình chính sách) thay vì điều chỉnh toàn bộ LLM có kích thước lớn.
4.3. Tính linh hoạt
DSP có thể được áp dụng cho nhiều tác vụ khác nhau và có thể dễ dàng điều chỉnh để đáp ứng các yêu cầu cụ thể. Mô hình chính sách có thể được huấn luyện lại cho các tác vụ mới mà không cần thay đổi LLM.
4.4. Khả năng tùy chỉnh theo từng trường hợp
DSP tạo ra kích thích định hướng cho từng đầu vào cụ thể, cho phép tùy chỉnh theo từng trường hợp. Điều này khác với các phương pháp khác thường áp dụng cùng một chiến lược cho tất cả các đầu vào.
5. Thách thức và hạn chế
Mặc dù DSP mang lại nhiều lợi ích, phương pháp này vẫn còn một số thách thức và hạn chế:
5.1. Phụ thuộc vào chất lượng của mô hình chính sách
Hiệu quả của DSP phụ thuộc nhiều vào chất lượng của mô hình chính sách. Nếu mô hình chính sách không được huấn luyện tốt, nó có thể tạo ra các kích thích định hướng không hiệu quả hoặc thậm chí gây hiểu nhầm cho LLM.
5.2. Cần dữ liệu huấn luyện chất lượng cao
Để huấn luyện mô hình chính sách hiệu quả, cần có dữ liệu huấn luyện chất lượng cao và phù hợp với tác vụ. Việc thu thập và chuẩn bị dữ liệu như vậy có thể tốn kém và mất thời gian.
5.3. Khó khăn trong việc đánh giá hiệu quả
Đánh giá hiệu quả của DSP có thể phức tạp, đặc biệt là khi so sánh với các phương pháp khác. Cần có các phương pháp đánh giá toàn diện để xác định liệu DSP có thực sự cải thiện hiệu suất của LLM hay không.
6. Nghiên cứu và phát triển trong tương lai
Các hướng nghiên cứu và phát triển tiềm năng cho DSP trong tương lai bao gồm:
6.1. Cải thiện mô hình chính sách
Nghiên cứu về cách cải thiện mô hình chính sách, bao gồm việc sử dụng các kiến trúc mô hình tiên tiến hơn và phương pháp huấn luyện hiệu quả hơn.
6.2. Mở rộng phạm vi ứng dụng
Khám phá các ứng dụng mới của DSP trong các lĩnh vực khác nhau, từ y tế đến giáo dục, từ luật pháp đến tài chính.
6.3. Kết hợp với các phương pháp khác
Nghiên cứu về cách kết hợp DSP với các phương pháp khác, như tinh chỉnh tham số hoặc học từ ít mẫu (few-shot learning), để tạo ra các giải pháp toàn diện hơn.
7. Kết luận
Directional Stimulus Prompting (DSP) là một phương pháp đầy hứa hẹn trong việc hướng dẫn các mô hình ngôn ngữ lớn tạo ra kết quả mong muốn. Bằng cách sử dụng một mô hình chính sách nhỏ hơn để tạo ra các kích thích định hướng, DSP cho phép tùy chỉnh LLM mà không cần truy cập vào cấu trúc bên trong của chúng.
Mặc dù còn một số thách thức, DSP đã chứng minh hiệu quả trong nhiều tác vụ xử lý ngôn ngữ tự nhiên và có tiềm năng ứng dụng rộng rãi trong tương lai. Với sự phát triển liên tục của công nghệ AI và ngày càng nhiều mô hình ngôn ngữ lớn được phát triển, DSP sẽ đóng vai trò quan trọng trong việc giúp người dùng tận dụng tối đa tiềm năng của các mô hình này.
Tài liệu tham khảo
- Li, Z., et al. (2023). Guiding Large Language Models via Directional Stimulus Prompting. Proceedings of the Neural Information Processing Systems (NeurIPS) 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/c5601d99ed028448f29d1dae2e4a926d-Paper-Conference.pdf
- Leezekun. (2023). Directional-Stimulus-Prompting: [NeurIPS 2023]. GitHub Repository. https://github.com/Leezekun/Directional-Stimulus-Prompting
- Prompt Engineering Guide. (2023). Directional Stimulus Prompting. https://promptingguide.ai/techniques/dsp
- IBM. (2023). What is directional stimulus prompting (DSP)? https://ibm.com/think/topics/directional-stimulus-prompting
- NeurIPS. (2023). Guiding Large Language Models via Directional Stimulus Prompting. https://neurips.cc/virtual/2023/poster/71484