Reflexion trong Prompt Engineering: Kỹ thuật Tự Phản Tư cho Mô Hình Ngôn Ngữ Lớn
Reflexion là một kỹ thuật tiên tiến trong prompt engineering giúp nâng cao khả năng tự đánh giá và cải thiện kết quả của mô hình ngôn ngữ lớn thông qua cơ chế phản hồi ngôn ngữ và tự phản tư, mang lại hiệu suất vượt trội trong giải quyết vấn đề phức tạp.
1. Giới thiệu về Reflexion
Reflexion là một framework được phát triển để tăng cường khả năng của các tác tử (agent) dựa trên ngôn ngữ thông qua phản hồi ngôn ngữ. Theo nghiên cứu của Shinn và cộng sự (2023), "Reflexion là một mô hình mới cho việc 'tăng cường bằng lời nói' (verbal reinforcement) mà tham số hóa một chính sách (policy) như là bộ nhớ mã hóa của tác tử kết hợp với lựa chọn các tham số của mô hình ngôn ngữ lớn (LLM)."
Reflexion được thiết kế để mô phỏng khả năng tự phản tư của con người - một đặc điểm quan trọng trong quá trình học tập và giải quyết vấn đề. Khi con người gặp khó khăn, chúng ta thường phân tích lỗi, đánh giá cách tiếp cận và điều chỉnh phương pháp. Reflexion mang cơ chế tương tự vào các mô hình ngôn ngữ lớn.
2. Cơ chế hoạt động của Reflexion
2.1. Nguyên lý cơ bản
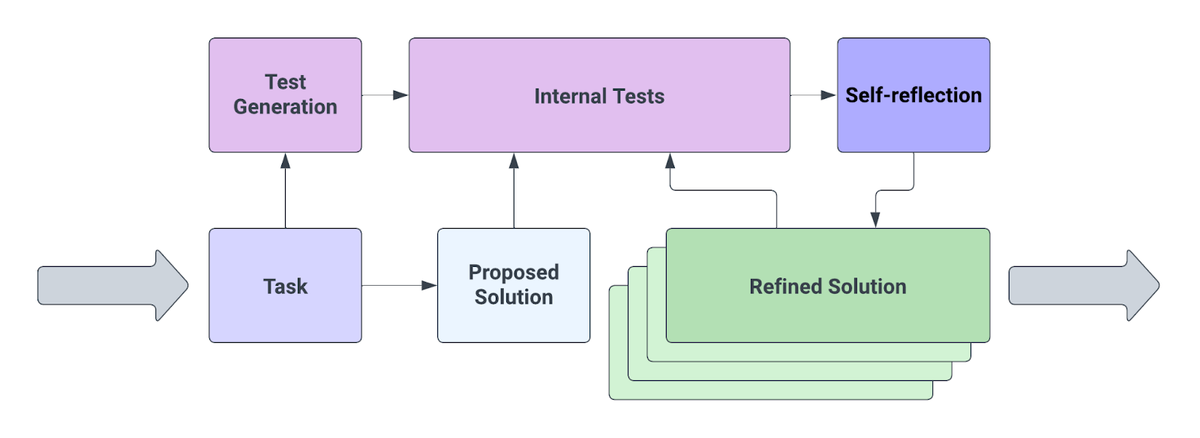
Ở cấp độ cao, Reflexion chuyển đổi phản hồi (dưới dạng ngôn ngữ tự do hoặc giá trị vô hướng) từ môi trường thành phản hồi ngôn ngữ, còn được gọi là tự phản tư (self-reflection), được cung cấp làm ngữ cảnh cho tác tử LLM trong lần thử tiếp theo.
Quy trình hoạt động của Reflexion bao gồm ba thành phần chính:
- Bộ nhớ động (Dynamic Memory): Lưu trữ các trải nghiệm, phản hồi và kết quả từ các lần thử trước đó.
- Khả năng tự phản tư (Self-Reflection): Phân tích các lỗi, đánh giá hiệu suất và đề xuất cải tiến.
- Tăng cường bằng lời nói (Verbal Reinforcement): Sử dụng phản hồi ngôn ngữ để điều chỉnh hành vi của tác tử.
2.2. Quy trình thực hiện
Quy trình Reflexion thường diễn ra theo các bước sau:
- Thực hiện nhiệm vụ: Tác tử LLM thực hiện nhiệm vụ được giao.
- Nhận phản hồi: Tác tử nhận phản hồi về hiệu suất của mình (từ môi trường hoặc đánh giá nội bộ).
- Tự phản tư: Tác tử phân tích hiệu suất của mình, xác định lỗi và nguyên nhân.
- Cập nhật bộ nhớ: Kết quả phản tư được lưu vào bộ nhớ động.
- Điều chỉnh phương pháp: Tác tử sử dụng thông tin từ bộ nhớ để cải thiện cách tiếp cận trong lần thử tiếp theo.
- Lặp lại: Quá trình được lặp lại cho đến khi đạt được kết quả mong muốn.
3. Ứng dụng của Reflexion trong Prompt Engineering
3.1. Cải thiện giải quyết vấn đề phức tạp
Reflexion đặc biệt hiệu quả trong việc giải quyết các vấn đề phức tạp không có lời giải rõ ràng. Thay vì chỉ dựa vào một lần thử duy nhất, Reflexion cho phép mô hình cải thiện dần dần thông qua nhiều lần lặp, tương tự như cách con người học hỏi từ kinh nghiệm.
Ví dụ, trong các bài toán lập trình phức tạp như trên LeetCode, Reflexion đã giúp cải thiện đáng kể tỷ lệ thành công của các mô hình ngôn ngữ lớn bằng cách cho phép chúng phân tích lỗi trong mã và điều chỉnh phương pháp.
3.2. Tăng cường học tập từ phản hồi
Reflexion tạo ra một cơ chế học tập từ phản hồi hiệu quả. Thay vì chỉ nhận phản hồi dưới dạng đúng/sai, tác tử được khuyến khích phân tích sâu hơn về nguyên nhân thành công hoặc thất bại, từ đó rút ra bài học có giá trị cho các nhiệm vụ tương tự trong tương lai.
3.3. Cải thiện độ chính xác và giảm thiên kiến
Nghiên cứu gần đây của Liu và cộng sự (2024) đã chỉ ra rằng tự phản tư có thể dẫn đến các phản hồi an toàn hơn (giảm 75,8% phản hồi độc hại trong khi vẫn duy trì 97,8% phản hồi không độc hại) và ít thiên kiến hơn. Điều này cho thấy tiềm năng của Reflexion trong việc tạo ra các hệ thống AI có trách nhiệm và đáng tin cậy hơn.
4. Cách triển khai Reflexion trong thực tế
4.1. Thiết kế prompt tự phản tư
Để triển khai Reflexion, cần thiết kế các prompt khuyến khích mô hình tự đánh giá và phản tư. Dưới đây là một mẫu prompt cơ bản:
[Nhiệm vụ ban đầu]
Kết quả của bạn: [Kết quả]
Phản hồi: [Phản hồi về kết quả]
Hãy phản tư về kết quả của bạn:
1. Những lỗi nào bạn đã mắc phải?
2. Tại sao những lỗi này xảy ra?
3. Làm thế nào bạn có thể cải thiện phương pháp của mình?
4. Hãy đề xuất một cách tiếp cận mới dựa trên phản tư của bạn.
4.2. Tích hợp bộ nhớ động
Để tận dụng tối đa Reflexion, cần tích hợp bộ nhớ động để lưu trữ các phản tư trước đó. Điều này có thể được thực hiện bằng cách duy trì một ngữ cảnh mở rộng bao gồm các lần thử và phản tư trước đó, hoặc thông qua các cơ chế bộ nhớ chuyên biệt trong các framework tác tử như LangChain.
4.3. Kỹ thuật RePrompt
Một biến thể của Reflexion là RePrompt, một phương pháp tối ưu hóa các hướng dẫn từng bước trong prompt dựa trên lịch sử trò chuyện thu được từ tương tác và phản tư với các tác tử LLM. RePrompt thực hiện một cách tiếp cận tương tự "gradient descent" để cải thiện chất lượng prompt theo thời gian.
5. Ví dụ thực tế về Reflexion
5.1. Giải quyết bài toán lập trình
Trong nghiên cứu gốc của Shinn và cộng sự, Reflexion được áp dụng để giải quyết các bài toán lập trình khó trên LeetCode. Dưới đây là một ví dụ đơn giản về quy trình:
- Nhiệm vụ ban đầu: Viết một hàm tìm số Fibonacci thứ n.
- Lần thử đầu tiên: Mô hình tạo ra một giải pháp đệ quy đơn giản nhưng không hiệu quả.
- Phản hồi: "Giải pháp của bạn chính xác nhưng không hiệu quả cho các giá trị n lớn do tính toán trùng lặp."
- Tự phản tư: "Tôi đã sử dụng phương pháp đệ quy đơn giản, nhưng điều này dẫn đến tính toán trùng lặp. Tôi cần sử dụng kỹ thuật ghi nhớ (memoization) hoặc phương pháp lặp để tránh tính toán lại các giá trị đã biết."
- Lần thử thứ hai: Mô hình tạo ra một giải pháp sử dụng kỹ thuật ghi nhớ hoặc phương pháp lặp, cải thiện đáng kể hiệu suất.
5.2. Cải thiện phản hồi an toàn
Reflexion cũng được sử dụng để cải thiện tính an toàn của các phản hồi từ mô hình ngôn ngữ lớn. Khi nhận được một câu hỏi tiềm ẩn rủi ro, mô hình có thể sử dụng tự phản tư để đánh giá các hậu quả tiềm ẩn của phản hồi trước khi đưa ra câu trả lời cuối cùng.
6. Ưu điểm và thách thức của Reflexion
6.1. Ưu điểm
- Cải thiện hiệu suất: Reflexion đã được chứng minh là cải thiện đáng kể hiệu suất của các mô hình ngôn ngữ lớn trong nhiều nhiệm vụ phức tạp.
- Học tập liên tục: Cho phép mô hình học hỏi và cải thiện dần dần thông qua trải nghiệm.
- Tăng tính minh bạch: Quá trình tự phản tư cung cấp cái nhìn sâu sắc về lý do tại sao mô hình đưa ra quyết định cụ thể.
- Giảm thiên kiến: Tự phản tư giúp mô hình nhận biết và giảm thiểu các thiên kiến tiềm ẩn.
6.2. Thách thức
- Chi phí tính toán: Quá trình lặp đi lặp lại đòi hỏi nhiều tài nguyên tính toán hơn.
- Thiết kế prompt phức tạp: Tạo ra các prompt hiệu quả cho tự phản tư đòi hỏi kỹ năng và kinh nghiệm.
- Bùng nổ ngữ cảnh: Khi bộ nhớ tích lũy, kích thước ngữ cảnh có thể vượt quá giới hạn của mô hình.
- Đánh giá khách quan: Đôi khi khó đánh giá liệu tự phản tư có thực sự dẫn đến cải thiện hay không.
7. Tương lai của Reflexion trong Prompt Engineering
Reflexion đại diện cho một bước tiến quan trọng trong việc phát triển các tác tử AI tự chủ và có khả năng học hỏi. Trong tương lai, chúng ta có thể kỳ vọng:
- Tích hợp sâu hơn với các hệ thống bộ nhớ: Phát triển các cơ chế bộ nhớ tinh vi hơn để lưu trữ và truy xuất hiệu quả các phản tư trước đó.
- Tự phản tư đa cấp độ: Mở rộng Reflexion để bao gồm nhiều cấp độ phản tư, từ chi tiết kỹ thuật đến chiến lược cấp cao.
- Kết hợp với các kỹ thuật khác: Tích hợp Reflexion với các kỹ thuật prompt engineering khác như Chain-of-Thought, Tree of Thoughts, và ReAct để tạo ra các tác tử mạnh mẽ hơn.
- Ứng dụng trong các lĩnh vực mới: Mở rộng việc sử dụng Reflexion sang các lĩnh vực như giáo dục, y tế và nghiên cứu khoa học.
8. Kết luận
Reflexion đại diện cho một bước tiến quan trọng trong prompt engineering, mang lại khả năng tự phản tư và cải thiện liên tục cho các mô hình ngôn ngữ lớn. Bằng cách mô phỏng quá trình học tập từ kinh nghiệm của con người, Reflexion cho phép các tác tử AI giải quyết các vấn đề phức tạp hiệu quả hơn và đưa ra các phản hồi an toàn, chính xác hơn.
Khi tiếp tục phát triển và tinh chỉnh, Reflexion có tiềm năng trở thành một công cụ không thể thiếu trong bộ công cụ prompt engineering, giúp thu hẹp khoảng cách giữa trí tuệ nhân tạo và khả năng học tập, thích nghi của con người.
Tài liệu tham khảo
- Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: an autonomous agent with dynamic memory and self-reflection. arXiv:2303.11366v1. https://arxiv.org/abs/2303.11366v1
- Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366. https://arxiv.org/pdf/2303.11366
- Liu, F. et al. (2024). Self-Reflection Makes Large Language Models Safer, Less Biased. arXiv:2406.10400. https://arxiv.org/abs/2406.10400
- Prompt Engineering Guide. (2024). Reflexion. https://promptingguide.ai/techniques/reflexion
- Prompt Engineering. (2023). Reflexion: An Iterative Approach to LLM Problem-Solving. https://promptengineering.org/reflexion-an-iterative-approach-to-llm-problem-solving
- Tyrie, R. (2023). Using ChatGPT and checking your work with "Reflexion". Better Prompt Engineering. https://robtyrie.medium.com/using-chatgpt-and-checking-yout-work-with-reflexion-better-prompt-engineering-788ae7f88222
- LangChain Blog. (2024). Reflection Agents. https://blog.langchain.dev/reflection-agents
- Mazzocchi, S. (2024). On The Surprising Power of Self-reflection in Large Language Models. Linotype. https://linotype.substack.com/p/on-the-surprising-power-of-self-reflection