Query Transformation trong RAG: Kỹ thuật nâng cao hiệu suất truy xuất thông tin
Query Transformation (Biến đổi Truy vấn) là một kỹ thuật quan trọng trong hệ thống Retrieval Augmented Generation (RAG), giúp cải thiện đáng kể chất lượng truy xuất thông tin bằng cách biến đổi câu truy vấn ban đầu của người dùng thành các dạng truy vấn hiệu quả hơn
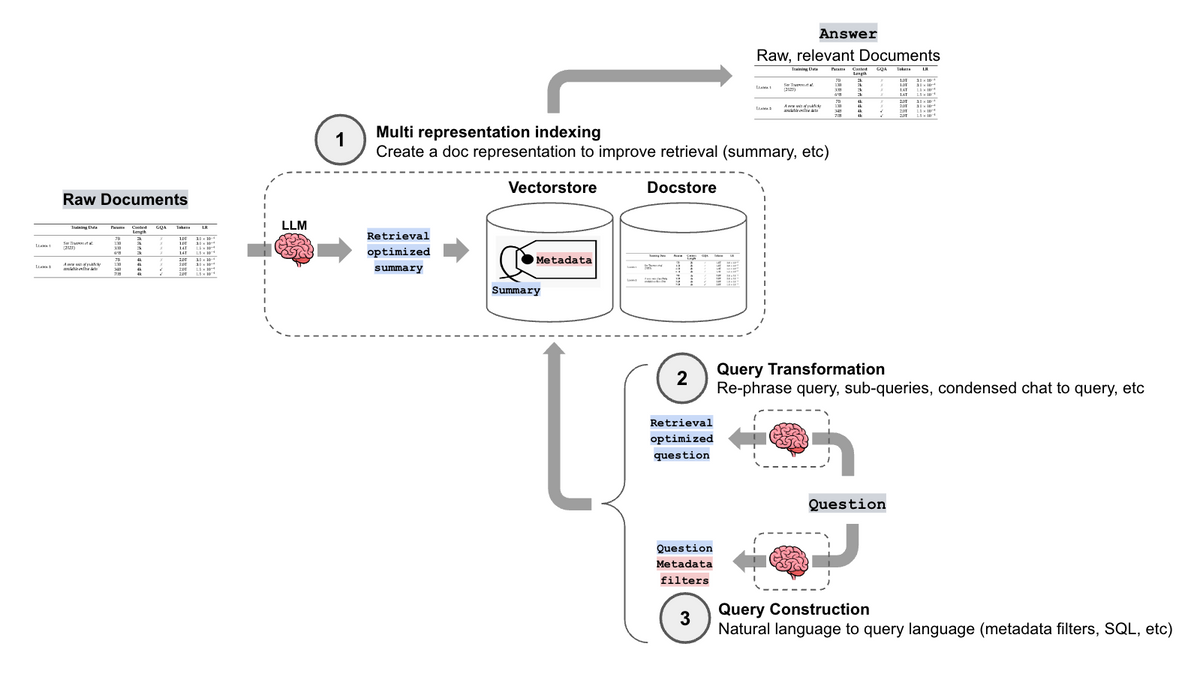
1. Giới thiệu về Query Transformation trong RAG
1.1. Vai trò của Query Transformation
Trong các hệ thống RAG truyền thống, quá trình truy xuất thông tin thường gặp nhiều thách thức khi người dùng đưa ra các câu hỏi không rõ ràng, thiếu chính xác hoặc quá phức tạp. Query Transformation đóng vai trò then chốt trong việc khắc phục những hạn chế này bằng cách:
- Làm rõ ý định thực sự của người dùng
- Mở rộng phạm vi tìm kiếm để bao quát nhiều khía cạnh liên quan
- Phân tách các câu hỏi phức tạp thành các câu hỏi đơn giản hơn
- Tạo ra các truy vấn có cấu trúc phù hợp hơn với cơ chế truy xuất
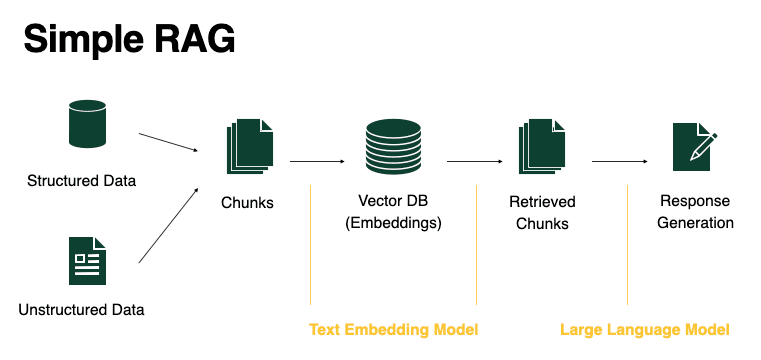
Theo nghiên cứu từ LangChain Blog (2023), các hệ thống RAG cơ bản thường chia tài liệu thành các đoạn nhỏ, nhúng chúng vào không gian vector, và truy xuất các đoạn có độ tương đồng ngữ nghĩa cao với câu hỏi của người dùng. Tuy nhiên, phương pháp này có thể gặp khó khăn khi câu hỏi được diễn đạt không tối ưu.
1.2. Lợi ích của Query Transformation
- Cải thiện độ chính xác: Tăng khả năng truy xuất các tài liệu liên quan nhất
- Mở rộng phạm vi: Bao quát nhiều khía cạnh của vấn đề hơn so với truy vấn gốc
- Xử lý câu hỏi phức tạp: Phân tách thành các câu hỏi đơn giản hơn để truy xuất hiệu quả
- Khắc phục truy vấn không rõ ràng: Làm rõ và cụ thể hóa các truy vấn mơ hồ
- Tăng cường ngữ cảnh: Bổ sung thông tin nền tảng cần thiết
2. Các kỹ thuật Query Transformation phổ biến
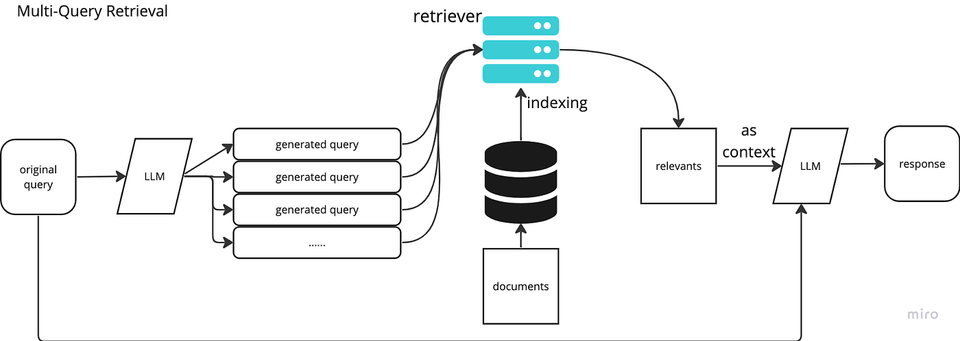
2.1. Multi-Query Generation (Tạo nhiều truy vấn)
Multi-Query Generation là kỹ thuật sử dụng mô hình ngôn ngữ lớn (LLM) để tạo ra nhiều phiên bản khác nhau của câu truy vấn gốc, nhằm mở rộng phạm vi tìm kiếm và tăng khả năng truy xuất thông tin liên quan.
Nguyên lý hoạt động:
- Nhận câu truy vấn gốc từ người dùng
- Sử dụng LLM để tạo ra nhiều biến thể của câu truy vấn (thường từ 3-5 biến thể)
- Thực hiện truy xuất với mỗi biến thể
- Kết hợp và xếp hạng kết quả truy xuất
Ví dụ:
Truy vấn gốc: "Làm thế nào để cải thiện hiệu suất của mô hình RAG?"
Các biến thể có thể được tạo ra:
- "Các kỹ thuật tối ưu hóa hiệu suất trong hệ thống RAG"
- "Phương pháp nâng cao độ chính xác của Retrieval Augmented Generation"
- "Những thách thức phổ biến và giải pháp trong việc triển khai RAG"
- "So sánh các phương pháp cải thiện hiệu quả truy xuất trong RAG"
Theo nghiên cứu từ Dev.to (2024), kỹ thuật này có thể cải thiện đáng kể độ bao phủ của kết quả truy xuất, đặc biệt đối với các câu hỏi phức tạp.
2.2. HyDE (Hypothetical Document Embeddings)
HyDE là một kỹ thuật sáng tạo sử dụng LLM để tạo ra một "tài liệu giả thuyết" dựa trên câu truy vấn, sau đó sử dụng embedding của tài liệu này để truy xuất thông tin thay vì sử dụng trực tiếp embedding của câu truy vấn.
Nguyên lý hoạt động:
- Nhận câu truy vấn từ người dùng
- Sử dụng LLM để tạo ra một "tài liệu giả thuyết" - một đoạn văn bản mô tả câu trả lời lý tưởng cho câu hỏi
- Tạo embedding cho tài liệu giả thuyết này
- Sử dụng embedding của tài liệu giả thuyết để tìm kiếm trong cơ sở dữ liệu
Ưu điểm:
- Khắc phục khoảng cách ngữ nghĩa giữa câu truy vấn và tài liệu
- Đặc biệt hiệu quả với các câu hỏi phức tạp hoặc trừu tượng
- Tăng cường ngữ cảnh cho quá trình truy xuất
Theo Medium (2024), HyDE đã chứng minh hiệu quả vượt trội trong các bài kiểm tra truy xuất thông tin, đặc biệt khi làm việc với các câu hỏi phức tạp mà các phương pháp truyền thống gặp khó khăn.
Ví dụ:
Truy vấn: "Tác động của biến đổi khí hậu đến nông nghiệp ở Đồng bằng sông Cửu Long"
Tài liệu giả thuyết được tạo ra:
Biến đổi khí hậu đang gây ra nhiều thách thức nghiêm trọng cho nông nghiệp ở Đồng bằng sông Cửu Long. Nhiệt độ tăng, mực nước biển dâng và xâm nhập mặn đang làm giảm diện tích đất canh tác và ảnh hưởng đến năng suất cây trồng. Các nghiên cứu gần đây cho thấy sản lượng lúa có thể giảm 6-12% trong những thập kỷ tới. Nông dân đang phải thích ứng bằng cách chuyển đổi cơ cấu cây trồng, áp dụng giống chịu mặn và phát triển các mô hình canh tác thông minh với khí hậu...
2.3. Step-Back Prompting (Đặt câu hỏi lùi bước)
Step-Back Prompting là kỹ thuật tạo ra một câu hỏi "lùi một bước" - trừu tượng hóa và mở rộng phạm vi của câu hỏi gốc để thu thập thông tin nền tảng cần thiết.
Nguyên lý hoạt động:
- Nhận câu truy vấn cụ thể từ người dùng
- Sử dụng LLM để tạo ra một câu hỏi "lùi bước" trừu tượng hơn, bao quát hơn
- Thực hiện truy xuất với cả câu hỏi gốc và câu hỏi lùi bước
- Kết hợp kết quả để tạo ra câu trả lời toàn diện hơn
Ví dụ:
Truy vấn gốc: "Làm thế nào để tối ưu hóa hyperparameter trong mô hình BERT?"
Câu hỏi lùi bước: "Các nguyên tắc cơ bản về tối ưu hóa hyperparameter trong mô hình học sâu là gì?"
Theo LangChain Blog (2023), kỹ thuật này đặc biệt hữu ích khi người dùng đặt câu hỏi quá cụ thể mà không cung cấp đủ ngữ cảnh, hoặc khi câu trả lời đòi hỏi kiến thức nền tảng để hiểu đầy đủ.
2.4. Query Decomposition (Phân tách truy vấn)
Query Decomposition là kỹ thuật phân tách câu hỏi phức tạp thành nhiều câu hỏi đơn giản hơn, dễ truy xuất hơn, sau đó tổng hợp kết quả để tạo ra câu trả lời toàn diện.
Nguyên lý hoạt động:
- Nhận câu truy vấn phức tạp từ người dùng
- Sử dụng LLM để phân tích và phân tách thành các câu hỏi con đơn giản hơn
- Thực hiện truy xuất riêng biệt cho từng câu hỏi con
- Tổng hợp kết quả từ tất cả các câu hỏi con để tạo ra câu trả lời cuối cùng
Ví dụ:
Truy vấn phức tạp: "So sánh hiệu suất và chi phí triển khai của các mô hình RAG và fine-tuning cho ứng dụng hỏi đáp y tế"
Phân tách thành:
- "Hiệu suất của mô hình RAG trong ứng dụng hỏi đáp y tế là gì?"
- "Chi phí triển khai mô hình RAG cho ứng dụng y tế là bao nhiêu?"
- "Hiệu suất của phương pháp fine-tuning trong ứng dụng hỏi đáp y tế là gì?"
- "Chi phí triển khai mô hình fine-tuning cho ứng dụng y tế là bao nhiêu?"
- "Các tiêu chí so sánh giữa RAG và fine-tuning trong lĩnh vực y tế?"
Theo GitHub (2024), kỹ thuật này đặc biệt hiệu quả với các câu hỏi phức tạp đòi hỏi thông tin từ nhiều lĩnh vực hoặc khía cạnh khác nhau.
3. Triển khai Query Transformation trong hệ thống RAG
3.1. Kiến trúc tổng thể
Một hệ thống RAG tích hợp Query Transformation thường có kiến trúc như sau:
Truy vấn người dùng → Query Transformation → Truy xuất thông tin → Tổng hợp kết quả → Tạo câu trả lời
Trong đó, thành phần Query Transformation có thể bao gồm một hoặc nhiều kỹ thuật đã đề cập ở trên.
3.2. Triển khai Multi-Query Generation
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# Khởi tạo mô hình
llm = OpenAI(temperature=0.7)
# Tạo template cho prompt
multi_query_template = """
Dựa trên câu hỏi gốc của người dùng, hãy tạo ra {num_queries} câu truy vấn khác nhau
để mở rộng phạm vi tìm kiếm và tăng khả năng truy xuất thông tin liên quan.
Các câu truy vấn nên khác nhau về cách diễn đạt và tập trung vào các khía cạnh khác nhau của vấn đề.
Câu hỏi gốc: {original_query}
Các câu truy vấn mới (chỉ liệt kê các câu truy vấn, mỗi câu một dòng):
"""
prompt = PromptTemplate(
input_variables=["original_query", "num_queries"],
template=multi_query_template
)
def generate_multiple_queries(original_query, num_queries=3):
formatted_prompt = prompt.format(original_query=original_query, num_queries=num_queries)
response = llm(formatted_prompt)
# Xử lý response để tách thành danh sách các câu truy vấn
queries = [q.strip() for q in response.strip().split('\n') if q.strip()]
return queries
3.3. Triển khai HyDE
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# Khởi tạo các thành phần
llm = OpenAI(temperature=0.1)
embeddings = OpenAIEmbeddings()
# Template cho việc tạo tài liệu giả thuyết
hyde_template = """
Dựa trên câu hỏi sau, hãy viết một đoạn văn ngắn mô tả câu trả lời lý tưởng.
Đoạn văn này nên chứa thông tin chính xác, đầy đủ và liên quan đến câu hỏi.
Câu hỏi: {query}
Đoạn văn trả lời:
"""
prompt = PromptTemplate(
input_variables=["query"],
template=hyde_template
)
def hyde_retrieval(query, vectorstore):
# Tạo tài liệu giả thuyết
formatted_prompt = prompt.format(query=query)
hypothetical_doc = llm(formatted_prompt)
# Sử dụng tài liệu giả thuyết để truy xuất
docs = vectorstore.similarity_search(hypothetical_doc, k=5)
return docs
3.4. Triển khai Step-Back Prompting
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# Khởi tạo mô hình
llm = OpenAI(temperature=0.3)
# Template cho việc tạo câu hỏi lùi bước
step_back_template = """
Dựa trên câu hỏi cụ thể sau, hãy tạo ra một câu hỏi "lùi một bước" - trừu tượng hơn,
tổng quát hơn và bao quát hơn - để thu thập thông tin nền tảng cần thiết.
Câu hỏi gốc: {original_query}
Câu hỏi lùi bước:
"""
prompt = PromptTemplate(
input_variables=["original_query"],
template=step_back_template
)
def generate_step_back_query(original_query):
formatted_prompt = prompt.format(original_query=original_query)
step_back_query = llm(formatted_prompt)
return step_back_query.strip()
3.5. Triển khai Query Decomposition
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# Khởi tạo mô hình
llm = OpenAI(temperature=0.3)
# Template cho việc phân tách câu hỏi
decomposition_template = """
Phân tách câu hỏi phức tạp sau thành các câu hỏi đơn giản hơn, dễ truy xuất hơn.
Mỗi câu hỏi con nên tập trung vào một khía cạnh cụ thể của vấn đề.
Câu hỏi phức tạp: {complex_query}
Các câu hỏi đơn giản hơn (liệt kê từng câu, mỗi câu một dòng):
"""
prompt = PromptTemplate(
input_variables=["complex_query"],
template=decomposition_template
)
def decompose_query(complex_query):
formatted_prompt = prompt.format(complex_query=complex_query)
response = llm(formatted_prompt)
# Xử lý response để tách thành danh sách các câu hỏi con
sub_queries = [q.strip() for q in response.strip().split('\n') if q.strip()]
return sub_queries
4. So sánh hiệu quả của các kỹ thuật Query Transformation
4.1. Bảng so sánh
| Kỹ thuật | Ưu điểm | Nhược điểm | Tình huống phù hợp |
|---|---|---|---|
| Multi-Query Generation | - Mở rộng phạm vi tìm kiếm - Tăng độ bao phủ - Dễ triển khai |
- Tăng chi phí tính toán - Có thể tạo ra truy vấn không liên quan |
- Câu hỏi mơ hồ - Cần tìm kiếm toàn diện |
| HyDE | - Khắc phục khoảng cách ngữ nghĩa - Hiệu quả với câu hỏi phức tạp |
- Phụ thuộc vào chất lượng tài liệu giả thuyết - Chi phí tính toán cao |
- Câu hỏi phức tạp - Câu hỏi trừu tượng |
| Step-Back Prompting | - Bổ sung thông tin nền tảng - Cải thiện ngữ cảnh |
- Có thể quá rộng - Khó kiểm soát hướng truy vấn |
- Câu hỏi quá cụ thể - Thiếu ngữ cảnh |
| Query Decomposition | - Xử lý hiệu quả câu hỏi phức tạp - Tăng độ chính xác |
- Tăng số lượng truy vấn - Phức tạp trong việc tổng hợp kết quả |
- Câu hỏi đa khía cạnh - Câu hỏi phức tạp |
4.2. Kết quả thực nghiệm
Theo nghiên cứu từ Dev.to (2024), khi so sánh hiệu suất của các kỹ thuật Query Transformation trên bộ dữ liệu chuẩn:
- HyDE cải thiện độ chính xác truy xuất lên đến 25% so với phương pháp truyền thống
- Multi-Query Generation tăng độ bao phủ thông tin lên 35%
- Query Decomposition đặc biệt hiệu quả với câu hỏi phức tạp, cải thiện độ chính xác lên 30%
- Step-Back Prompting giúp tăng 20% khả năng cung cấp thông tin nền tảng cần thiết
5. Kết hợp các kỹ thuật Query Transformation
5.1. RAG Fusion
RAG Fusion là phương pháp kết hợp nhiều kỹ thuật Query Transformation để tận dụng ưu điểm của từng phương pháp. Một cách tiếp cận phổ biến là:
- Sử dụng Multi-Query Generation để tạo ra nhiều biến thể của câu truy vấn
- Áp dụng HyDE cho mỗi biến thể để tạo ra các tài liệu giả thuyết
- Thực hiện truy xuất với mỗi tài liệu giả thuyết
- Kết hợp và xếp hạng kết quả bằng thuật toán Reciprocal Rank Fusion
def rag_fusion(query, vectorstore):
# Bước 1: Tạo nhiều biến thể của câu truy vấn
query_variants = generate_multiple_queries(query, num_queries=3)
all_results = []
# Bước 2 & 3: Áp dụng HyDE và truy xuất
for variant in query_variants:
# Tạo tài liệu giả thuyết
hypothetical_doc = generate_hypothetical_doc(variant)
# Truy xuất với tài liệu giả thuyết
results = vectorstore.similarity_search(hypothetical_doc, k=5)
all_results.extend(results)
# Bước 4: Kết hợp và xếp hạng kết quả
unique_results = {}
for doc in all_results:
if doc.id not in unique_results:
unique_results[doc.id] = doc
# Áp dụng thuật toán Reciprocal Rank Fusion
# (Triển khai thuật toán RRF ở đây)
return list(unique_results.values())
5.2. Adaptive Query Transformation
Adaptive Query Transformation là phương pháp tự động lựa chọn kỹ thuật Query Transformation phù hợp nhất dựa trên đặc điểm của câu truy vấn:
def adaptive_query_transformation(query):
# Phân tích đặc điểm của câu truy vấn
query_features = analyze_query(query)
# Lựa chọn kỹ thuật phù hợp
if query_features["complexity"] > 0.7:
# Câu hỏi phức tạp -> sử dụng Query Decomposition
return decompose_query(query)
elif query_features["abstractness"] > 0.6:
# Câu hỏi trừu tượng -> sử dụng HyDE
return generate_hypothetical_doc(query)
elif query_features["specificity"] > 0.8:
# Câu hỏi quá cụ thể -> sử dụng Step-Back Prompting
return generate_step_back_query(query)
else:
# Mặc định -> sử dụng Multi-Query Generation
return generate_multiple_queries(query)
6. Thách thức và giải pháp
6.1. Thách thức
- Chi phí tính toán cao: Các kỹ thuật Query Transformation thường đòi hỏi nhiều lần gọi LLM và truy xuất, dẫn đến chi phí tính toán cao.
- Độ trễ tăng: Thời gian phản hồi có thể tăng đáng kể do các bước xử lý bổ sung.
- Phụ thuộc vào chất lượng LLM: Hiệu quả của các kỹ thuật phụ thuộc nhiều vào chất lượng của mô hình ngôn ngữ được sử dụng.
- Khó đánh giá hiệu quả: Việc đánh giá khách quan hiệu quả của các kỹ thuật Query Transformation không đơn giản.
6.2. Giải pháp
- Tối ưu hóa hiệu suất:
- Sử dụng caching để lưu trữ kết quả trung gian
- Triển khai xử lý song song cho các truy vấn độc lập
- Sử dụng mô hình nhẹ hơn cho các bước trung gian
- Cân bằng độ trễ và chất lượng:
- Thiết lập ngưỡng thời gian tối đa cho mỗi bước
- Áp dụng early stopping khi đạt được kết quả đủ tốt
- Triển khai hệ thống phản hồi theo từng phần
- Cải thiện đánh giá:
- Xây dựng bộ dữ liệu chuẩn cho việc đánh giá
- Kết hợp đánh giá tự động và đánh giá của con người
- Theo dõi các chỉ số như độ chính xác, độ bao phủ, và thời gian phản hồi
7. Xu hướng phát triển và nghiên cứu mới
7.1. Xu hướng hiện tại
- Kết hợp Query Transformation với các kỹ thuật khác:
- Tích hợp với Re-ranking để cải thiện thứ tự kết quả
- Kết hợp với Contextual Compression để giảm nhiễu trong kết quả truy xuất
- Tự động hóa lựa chọn kỹ thuật:
- Phát triển các mô hình meta-learning để tự động chọn kỹ thuật tối ưu
- Áp dụng reinforcement learning để tối ưu hóa quá trình lựa chọn
- Cá nhân hóa Query Transformation:
- Điều chỉnh kỹ thuật dựa trên lịch sử tương tác của người dùng
- Học từ phản hồi của người dùng để cải thiện hiệu quả
7.2. Nghiên cứu mới
- RQ-RAG (Refine Query for RAG):
Theo nghiên cứu từ arXiv (2024), RQ-RAG là phương pháp mới tập trung vào việc học cách tinh chỉnh truy vấn thông qua quá trình huấn luyện có giám sát, giúp mô hình tự động điều chỉnh truy vấn dựa trên ngữ cảnh và mục tiêu cụ thể. - Multimodal Query Transformation:
Mở rộng các kỹ thuật Query Transformation để xử lý truy vấn đa phương thức (văn bản, hình ảnh, âm thanh), giúp cải thiện hiệu quả truy xuất trong các hệ thống RAG đa phương thức. - Domain-Specific Query Transformation:
Phát triển các kỹ thuật Query Transformation chuyên biệt cho từng lĩnh vực (y tế, luật pháp, tài chính...) để tận dụng đặc thù của từng lĩnh vực.
8. Kết luận
Query Transformation đóng vai trò quan trọng trong việc nâng cao hiệu quả của các hệ thống RAG, giúp khắc phục những hạn chế của phương pháp truy xuất truyền thống. Các kỹ thuật như Multi-Query Generation, HyDE, Step-Back Prompting và Query Decomposition mang lại những cải tiến đáng kể về độ chính xác và độ bao phủ của kết quả truy xuất.
Mặc dù còn đối mặt với nhiều thách thức về chi phí tính toán và độ trễ, nhưng với sự phát triển nhanh chóng của công nghệ và các nghiên cứu mới, Query Transformation đang ngày càng trở nên hiệu quả và dễ tiếp cận hơn. Các xu hướng như tự động hóa lựa chọn kỹ thuật, cá nhân hóa và mở rộng sang đa phương thức hứa hẹn sẽ mang lại những tiến bộ đáng kể trong tương lai.
Để triển khai thành công Query Transformation, các nhà phát triển cần hiểu rõ đặc điểm của ứng dụng, lựa chọn kỹ thuật phù hợp, và liên tục đánh giá, tinh chỉnh hệ thống dựa trên phản hồi thực tế. Với cách tiếp cận đúng đắn, Query Transformation có thể giúp các hệ thống RAG đạt được hiệu quả vượt trội, mang lại trải nghiệm người dùng tốt hơn và kết quả chính xác hơn.
Tài liệu tham khảo
- LangChain Blog. (2023). "Query Transformations". Truy xuất từ https://blog.langchain.dev/query-transformations
- Mathur, A. (2024). "Advanced RAG: Query Augmentation for Next-Level Search using LlamaIndex". Medium. Truy xuất từ https://akash-mathur.medium.com/advanced-rag-query-augmentation-for-next-level-search-using-llamaindex-d362fed7ecc3
- Li, J. (2024). "In-Depth Understanding of RAG Query Transformation Optimization: Multi-Query, Problem Decomposition, and Step-Back". Dev.to. Truy xuất từ https://dev.to/jamesli/in-depth-understanding-of-rag-query-transformation-optimization-multi-query-problem-decomposition-and-step-back-27jg
- Diamant, N. (2024). "Query Transformations for Improved Retrieval in RAG Systems". GitHub. Truy xuất từ https://github.com/NirDiamant/RAG_Techniques/blob/main/all_rag_techniques/query_transformations.ipynb
- Zilliz. (2024). "Better RAG with HyDE - Hypothetical Document Embeddings". Truy xuất từ https://zilliz.com/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings
- Analytics Vidhya. (2024). "Enhancing RAG with Hypothetical Document Embedding". Truy xuất từ https://analyticsvidhya.com/blog/2024/04/enhancing-rag-with-hypothetical-document-embedding
- Biswas, S. (2024). "Hypothetical Document Embeddings (HyDE)". LinkedIn. Truy xuất từ https://linkedin.com/pulse/hypothetical-document-embeddings-hyde-suman-biswas-5r0ye
- Microsoft. (2025). "Common retrieval augmented generation (RAG) techniques explained". Truy xuất từ https://microsoft.com/en-us/microsoft-cloud/blog/2025/02/04/common-retrieval-augmented-generation-rag-techniques-explained
- Spring AI Reference. (2024). "Retrieval Augmented Generation (RAG)". Truy xuất từ https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html
- Towards Data Science. (2024). "Advanced Query Transformations to Improve RAG". Truy xuất từ https://towardsdatascience.com/advanced-query-transformations-to-improve-rag-11adca9b19d1
- LlamaIndex. (2024). "Query Transformations". Truy xuất từ https://docs.llamaindex.ai/en/stable/optimizing/advanced_retrieval/query_transformations
- arXiv. (2024). "RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation". Truy xuất từ https://arxiv.org/html/2404.00610v1
- Haystack. (2024). "Hypothetical Document Embeddings (HyDE)". Truy xuất từ https://docs.haystack.deepset.ai/docs/hypothetical-document-embeddings-hyde
- Caesar, B. (2025). "Exploring RAG: Hypothetical Document Embeddings (HyDE)". Dev.to. Truy xuất từ https://dev.to/busycaesar/exploring-rag-hypothetical-document-embeddings-hyde-43an
- AI Engineering Academy. (2024). "Query Transformation (Llamaindex)". Truy xuất từ https://aiengineering.academy/RAG/06_Query_Transformation_RAG/query_transform_cookbook