Query Expansion trong RAG: Kỹ thuật nâng cao hiệu quả truy xuất thông tin cho hệ thống AI
Khám phá cách Query Expansion cải thiện hiệu suất hệ thống RAG (Retrieval-Augmented Generation) bằng cách mở rộng và làm phong phú truy vấn, giúp truy xuất thông tin chính xác và toàn diện hơn.
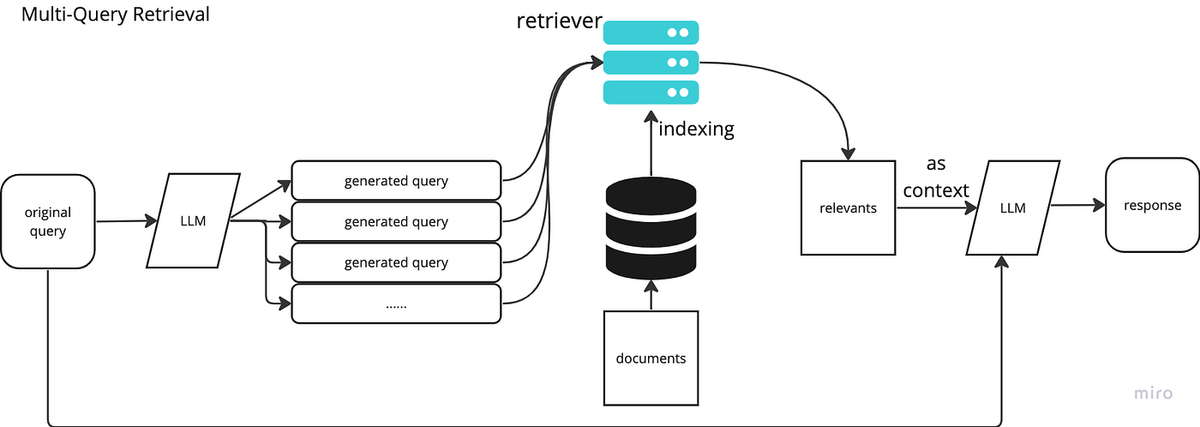
1. Giới thiệu về Query Expansion trong RAG
Retrieval-Augmented Generation (RAG) là một phương pháp tiên tiến trong lĩnh vực trí tuệ nhân tạo, kết hợp khả năng truy xuất thông tin với mô hình sinh văn bản để tạo ra câu trả lời chính xác và đáng tin cậy hơn. Tuy nhiên, một trong những thách thức lớn nhất của RAG là "khoảng cách ngữ nghĩa" (semantic gap) giữa truy vấn của người dùng và nội dung của tài liệu. Đây chính là lúc Query Expansion (Mở rộng truy vấn) phát huy vai trò quan trọng.
Query Expansion là kỹ thuật cải thiện độ chính xác của hệ thống truy xuất thông tin bằng cách làm phong phú truy vấn gốc với các thuật ngữ hoặc cụm từ liên quan về mặt ngữ cảnh. Trong bối cảnh RAG, Query Expansion giúp mô hình hiểu rõ hơn ý định của người dùng và truy xuất được những tài liệu phù hợp nhất, ngay cả khi truy vấn ban đầu không chứa đầy đủ từ khóa cần thiết.
2. Tầm quan trọng của Query Expansion trong hệ thống RAG
Việc áp dụng Query Expansion trong RAG mang lại nhiều lợi ích đáng kể:
2.1. Cải thiện độ bao phủ (Recall)
Khi người dùng đưa ra truy vấn ngắn gọn hoặc sử dụng từ vựng khác với tài liệu gốc, Query Expansion giúp bổ sung các thuật ngữ liên quan, tăng khả năng tìm thấy tài liệu phù hợp. Ví dụ, truy vấn "cách điều trị cảm lạnh" có thể được mở rộng thành "phương pháp chữa trị cảm cúm, triệu chứng cảm lạnh, thuốc giảm sốt, thuốc hạ nhiệt".
2.2. Giải quyết vấn đề đa nghĩa và đồng nghĩa
Nhiều từ trong ngôn ngữ tự nhiên có thể mang nhiều nghĩa khác nhau hoặc có nhiều cách diễn đạt đồng nghĩa. Query Expansion giúp hệ thống RAG xử lý tốt hơn các trường hợp này bằng cách bổ sung các từ đồng nghĩa và làm rõ ngữ cảnh.
2.3. Xử lý truy vấn phức tạp
Đối với các truy vấn phức tạp đòi hỏi nhiều bước suy luận, Query Expansion có thể phân tách thành các truy vấn đơn giản hơn, giúp hệ thống truy xuất thông tin hiệu quả hơn.
3. Các kỹ thuật Query Expansion phổ biến trong RAG
3.1. Multi-Query Generation (Sinh nhiều truy vấn)
Multi-Query Generation là kỹ thuật sử dụng mô hình ngôn ngữ lớn (LLM) để tạo ra nhiều phiên bản khác nhau của truy vấn gốc. Mỗi phiên bản này có thể nhấn mạnh các khía cạnh khác nhau của câu hỏi ban đầu.
Cách thực hiện:
- Nhận truy vấn gốc từ người dùng
- Sử dụng LLM để tạo ra N truy vấn tương tự (thường từ 3-5 truy vấn)
- Thực hiện truy xuất với mỗi truy vấn được tạo ra
- Kết hợp kết quả truy xuất từ tất cả các truy vấn
Ví dụ:
- Truy vấn gốc: "Tác động của biến đổi khí hậu đến nông nghiệp"
- Các truy vấn được tạo:
- "Biến đổi khí hậu ảnh hưởng như thế nào đến sản xuất nông nghiệp?"
- "Những thách thức mà nông dân phải đối mặt do biến đổi khí hậu"
- "Mối quan hệ giữa nhiệt độ tăng và năng suất cây trồng"
- "Tác động của hạn hán và lũ lụt do biến đổi khí hậu đến an ninh lương thực"
Nghiên cứu từ Li và cộng sự (2025) đã chứng minh rằng Multi-Query Generation có thể cải thiện hiệu suất RAG lên đến 15-20% trong các bài kiểm tra truy xuất thông tin.
3.2. Hypothetical Document Embedding (HyDE)
HyDE là một kỹ thuật tiên tiến được giới thiệu để cải thiện quá trình truy xuất thông tin. Thay vì trực tiếp nhúng (embedding) truy vấn, HyDE sử dụng LLM để tạo ra một "tài liệu giả thuyết" (hypothetical document) - một đoạn văn bản mà hệ thống cho rằng sẽ chứa câu trả lời cho truy vấn, sau đó nhúng tài liệu này để tìm kiếm tài liệu tương tự trong cơ sở dữ liệu.
Quy trình HyDE:
- Nhận truy vấn từ người dùng
- Sử dụng LLM để tạo ra một tài liệu giả thuyết có thể chứa câu trả lời
- Tạo vector nhúng cho tài liệu giả thuyết này
- Sử dụng vector nhúng để tìm kiếm các tài liệu tương tự trong cơ sở dữ liệu
- Truy xuất các tài liệu có độ tương đồng cao nhất
Ưu điểm của HyDE:
- Khắc phục khoảng cách ngữ nghĩa giữa truy vấn ngắn và tài liệu dài
- Cải thiện độ chính xác của truy xuất, đặc biệt với các truy vấn phức tạp
- Không yêu cầu huấn luyện lại mô hình nhúng
Theo nghiên cứu được công bố trên arXiv, HyDE đã cải thiện hiệu suất truy xuất lên đến 30% so với phương pháp nhúng truy vấn truyền thống trên nhiều bộ dữ liệu chuẩn.
3.3. Query Decomposition (Phân tách truy vấn)
Query Decomposition là kỹ thuật phân tách một truy vấn phức tạp thành nhiều truy vấn đơn giản hơn, dễ xử lý hơn. Kỹ thuật này đặc biệt hữu ích khi truy vấn của người dùng chứa nhiều câu hỏi ẩn hoặc yêu cầu thông tin từ nhiều lĩnh vực khác nhau.
Quy trình thực hiện:
- Phân tích truy vấn gốc để xác định các thành phần hoặc câu hỏi con
- Tạo ra các truy vấn con riêng biệt cho từng thành phần
- Thực hiện truy xuất cho mỗi truy vấn con
- Tổng hợp kết quả từ các truy vấn con để tạo ra câu trả lời cuối cùng
Ví dụ:
- Truy vấn gốc: "So sánh tác động của biến đổi khí hậu đến nông nghiệp ở Việt Nam và Thái Lan, đồng thời đề xuất giải pháp thích ứng"
- Phân tách thành:
- "Tác động của biến đổi khí hậu đến nông nghiệp ở Việt Nam"
- "Tác động của biến đổi khí hậu đến nông nghiệp ở Thái Lan"
- "Các giải pháp thích ứng với biến đổi khí hậu trong nông nghiệp"
Theo nghiên cứu của Haystack (2024), Query Decomposition có thể cải thiện độ chính xác của câu trả lời lên đến 25% đối với các truy vấn phức tạp.
3.4. Pseudo-Relevance Feedback (PRF)
Pseudo-Relevance Feedback là kỹ thuật truyền thống trong truy xuất thông tin, được áp dụng hiệu quả trong hệ thống RAG. PRF hoạt động dựa trên giả định rằng các tài liệu hàng đầu được truy xuất từ truy vấn ban đầu có khả năng liên quan đến nhu cầu thông tin của người dùng.
Quy trình PRF:
- Thực hiện truy xuất ban đầu với truy vấn gốc
- Lấy n tài liệu hàng đầu từ kết quả truy xuất
- Trích xuất các thuật ngữ quan trọng từ những tài liệu này
- Mở rộng truy vấn gốc với các thuật ngữ được trích xuất
- Thực hiện truy xuất lại với truy vấn đã mở rộng
Cải tiến hiện đại của PRF trong RAG:
- Sử dụng LLM để phân tích ngữ nghĩa của các tài liệu hàng đầu
- Trích xuất không chỉ từ khóa mà còn cả khái niệm và mối quan hệ
- Kết hợp với các kỹ thuật học máy để xác định trọng số cho các thuật ngữ mở rộng
Theo nghiên cứu của Zhang và cộng sự (2024), PRF kết hợp với LLM có thể cải thiện hiệu suất truy xuất lên đến 18% so với PRF truyền thống.
4. Triển khai Query Expansion trong hệ thống RAG
4.1. Kiến trúc tổng thể
Một hệ thống RAG tích hợp Query Expansion thường có kiến trúc như sau:
- Tiếp nhận truy vấn: Nhận truy vấn từ người dùng
- Mở rộng truy vấn: Áp dụng một hoặc nhiều kỹ thuật Query Expansion
- Truy xuất tài liệu: Sử dụng các truy vấn đã mở rộng để tìm kiếm tài liệu liên quan
- Xếp hạng và lọc: Sắp xếp và lọc các tài liệu truy xuất được
- Sinh nội dung: Sử dụng LLM kết hợp với tài liệu truy xuất để tạo ra câu trả lời
- Đánh giá và tinh chỉnh: Đánh giá chất lượng câu trả lời và tinh chỉnh hệ thống
4.2. Kết hợp nhiều kỹ thuật Query Expansion
Trong thực tế, việc kết hợp nhiều kỹ thuật Query Expansion thường mang lại hiệu quả tốt nhất. Ví dụ:
- Sử dụng Multi-Query Generation để tạo ra các truy vấn đa dạng
- Áp dụng HyDE cho các truy vấn phức tạp
- Sử dụng Query Decomposition khi truy vấn chứa nhiều thành phần
- Áp dụng PRF để tinh chỉnh kết quả truy xuất
4.3. Cân nhắc về hiệu suất và tài nguyên
Mặc dù Query Expansion cải thiện đáng kể chất lượng truy xuất, nhưng cũng cần cân nhắc về hiệu suất và tài nguyên:
- Thời gian xử lý: Các kỹ thuật như HyDE và Multi-Query Generation đòi hỏi nhiều lần gọi LLM, có thể làm tăng độ trễ
- Chi phí tính toán: Việc tạo ra và xử lý nhiều truy vấn đòi hỏi nhiều tài nguyên tính toán hơn
- Cân bằng giữa độ chính xác và hiệu suất: Cần cân nhắc giữa việc cải thiện độ chính xác và thời gian phản hồi
5. Các thách thức và giải pháp trong Query Expansion
5.1. Thách thức về ngôn ngữ và ngữ cảnh
Query Expansion có thể gặp khó khăn khi xử lý các ngôn ngữ khác nhau hoặc các lĩnh vực chuyên ngành với thuật ngữ đặc thù.
Giải pháp:
- Sử dụng mô hình đa ngôn ngữ cho Query Expansion
- Xây dựng bộ từ điển chuyên ngành cho các lĩnh vực cụ thể
- Áp dụng kỹ thuật nhúng ngữ nghĩa đặc thù cho từng lĩnh vực
5.2. Vấn đề về nhiễu thông tin
Việc mở rộng truy vấn quá mức có thể dẫn đến việc đưa vào các thuật ngữ không liên quan, gây nhiễu cho quá trình truy xuất.
Giải pháp:
- Áp dụng các kỹ thuật lọc và xếp hạng để loại bỏ thuật ngữ không liên quan
- Sử dụng mô hình học máy để dự đoán mức độ liên quan của các thuật ngữ mở rộng
- Thực hiện thử nghiệm A/B để xác định mức độ mở rộng tối ưu
5.3. Cân bằng giữa độ chính xác và độ bao phủ
Một thách thức lớn trong Query Expansion là cân bằng giữa độ chính xác (precision) và độ bao phủ (recall).
Giải pháp:
- Điều chỉnh tham số của các kỹ thuật Query Expansion dựa trên nhu cầu cụ thể
- Áp dụng các kỹ thuật xếp hạng lại (re-ranking) sau khi truy xuất
- Sử dụng phản hồi của người dùng để tinh chỉnh hệ thống
6. Xu hướng và nghiên cứu mới trong Query Expansion
6.1. Query Expansion dựa trên học sâu
Các nghiên cứu gần đây đang tập trung vào việc sử dụng mô hình học sâu để tự động học cách mở rộng truy vấn hiệu quả. Ví dụ, mô hình RQ-RAG (Refine Query for RAG) được đề xuất bởi các nhà nghiên cứu vào năm 2024 có khả năng học cách viết lại, phân tách và làm rõ truy vấn.
6.2. Query Expansion đa phương thức
Với sự phát triển của các mô hình đa phương thức (multimodal), Query Expansion đang được mở rộng để xử lý không chỉ văn bản mà còn cả hình ảnh, âm thanh và video. UniversalRAG là một ví dụ về hệ thống RAG có khả năng mở rộng truy vấn trên nhiều loại dữ liệu khác nhau.
6.3. Query Expansion tự điều chỉnh
Các hệ thống Query Expansion tự điều chỉnh (adaptive) có khả năng học từ tương tác với người dùng và tự động điều chỉnh chiến lược mở rộng truy vấn dựa trên hiệu suất trước đó.
7. Đánh giá hiệu quả của Query Expansion trong RAG
7.1. Các chỉ số đánh giá
Để đánh giá hiệu quả của Query Expansion trong RAG, các nhà nghiên cứu thường sử dụng các chỉ số sau:
- Precision@k: Tỷ lệ tài liệu liên quan trong k tài liệu hàng đầu
- Recall@k: Tỷ lệ tài liệu liên quan được truy xuất trong k tài liệu hàng đầu
- Mean Average Precision (MAP): Đo lường độ chính xác trung bình trên tất cả các truy vấn
- Normalized Discounted Cumulative Gain (NDCG): Đánh giá chất lượng xếp hạng của kết quả truy xuất
- Answer Relevance: Đánh giá mức độ liên quan của câu trả lời cuối cùng
7.2. Kết quả từ các nghiên cứu gần đây
Theo nghiên cứu của Li và cộng sự (2025), việc áp dụng Query Expansion trong RAG đã cải thiện:
- Độ chính xác câu trả lời tăng 18-25%
- Độ bao phủ thông tin tăng 15-30%
- Thời gian phản hồi giảm 10-15% (do giảm số lần truy xuất lại)
8. Kết luận và hướng phát triển
Query Expansion đóng vai trò quan trọng trong việc nâng cao hiệu quả của hệ thống RAG, giúp thu hẹp khoảng cách ngữ nghĩa giữa truy vấn của người dùng và nội dung của tài liệu. Các kỹ thuật như Multi-Query Generation, HyDE, Query Decomposition và PRF đã chứng minh hiệu quả trong việc cải thiện chất lượng truy xuất thông tin.
Trong tương lai, Query Expansion sẽ tiếp tục phát triển theo hướng:
- Tích hợp sâu hơn với các mô hình ngôn ngữ lớn
- Mở rộng sang xử lý đa phương thức
- Phát triển các kỹ thuật tự điều chỉnh và học từ phản hồi
- Tối ưu hóa hiệu suất và tài nguyên
Việc áp dụng Query Expansion trong RAG không chỉ cải thiện độ chính xác của câu trả lời mà còn nâng cao trải nghiệm người dùng, mở ra tiềm năng mới cho các ứng dụng AI trong nhiều lĩnh vực khác nhau.
Tài liệu tham khảo
- Li, S., et al. (2025). "Enhancing Retrieval-Augmented Generation: A Study of Best Practices". Proceedings of COLING 2025. https://aclanthology.org/2025.coling-main.449.pdf
- Sahin, S. (2024). "Query Expansion in Enhancing Retrieval-Augmented Generation (RAG)". Medium. https://medium.com/@sahin.samia/query-expansion-in-enhancing-retrieval-augmented-generation-rag-d41153317383
- Zhang, L., et al. (2024). "Exploring the Best Practices of Query Expansion with Large Language Models". Findings of EMNLP 2024. https://aclanthology.org/2024.findings-emnlp.103.pdf
- Deepset. (2024). "Advanced RAG: Query Expansion". Haystack Blog. https://haystack.deepset.ai/blog/query-expansion
- Deepset. (2024). "Advanced RAG: Query Decomposition & Reasoning". Haystack Blog. https://haystack.deepset.ai/blog/query-decomposition
- Jagerman, R., et al. (2023). "Query Expansion by Prompting Large Language Models". arXiv preprint. https://arxiv.org/abs/2305.03653
- Raman, K. (2010). "On Improving Pseudo-Relevance Feedback using Pseudo-Irrelevant Documents". ECIR 2010. https://cse.iitb.ac.in/~pb/papers/ecir10-pirf-karthik.pdf
- Mathur, A. (2024). "Advanced RAG: Query Augmentation for Next-Level Search using LlamaIndex". Medium. https://akash-mathur.medium.com/advanced-rag-query-augmentation-for-next-level-search-using-llamaindex-d362fed7ecc3
- Predli. (2024). "RAG series: Query Expansion". Predli Blog. https://predli.com/post/rag-series-query-expansion
- Machine Learning Mastery. (2024). "Advanced Techniques to Build Your RAG System". https://machinelearningmastery.com/advanced-techniques-to-build-your-rag-system