Multimodal Chain-of-Thought Prompting: Phương Pháp Lập Luận Đa Phương Thức Trong Các Mô Hình Ngôn Ngữ Lớn
Multimodal Chain-of-Thought (MCoT) Prompting - phương pháp lập luận theo chuỗi suy nghĩ đa phương thức, kết hợp thông tin từ nhiều dạng dữ liệu khác nhau để nâng cao khả năng lập luận của các mô hình ngôn ngữ lớn trong việc giải quyết các bài toán phức tạp.
1. Giới thiệu
Trong những năm gần đây, các mô hình ngôn ngữ lớn (LLMs) đã đạt được những tiến bộ đáng kể trong khả năng lập luận và giải quyết vấn đề. Một trong những kỹ thuật quan trọng góp phần vào sự tiến bộ này là Chain-of-Thought (CoT) Prompting - phương pháp hướng dẫn mô hình thực hiện lập luận từng bước để đi đến kết luận cuối cùng. Tuy nhiên, CoT truyền thống chủ yếu tập trung vào dữ liệu văn bản, trong khi nhiều bài toán trong thực tế đòi hỏi khả năng xử lý thông tin từ nhiều phương thức khác nhau như hình ảnh, âm thanh, video...
Multimodal Chain-of-Thought (MCoT) Prompting ra đời nhằm mở rộng khả năng lập luận của các mô hình ngôn ngữ lớn sang lĩnh vực đa phương thức, đặc biệt là kết hợp giữa văn bản và hình ảnh. Phương pháp này đã thu hút sự chú ý đáng kể từ cộng đồng nghiên cứu, đặc biệt trong bối cảnh phát triển các mô hình ngôn ngữ lớn đa phương thức (MLLMs).
2. Khái niệm cơ bản về Chain-of-Thought Prompting
Chain-of-Thought (CoT) Prompting là kỹ thuật hướng dẫn mô hình ngôn ngữ lớn thực hiện lập luận từng bước để giải quyết các bài toán phức tạp. Thay vì yêu cầu mô hình đưa ra câu trả lời trực tiếp, CoT khuyến khích mô hình chia nhỏ vấn đề thành các bước trung gian, tạo ra một "chuỗi suy nghĩ" trước khi đi đến kết luận cuối cùng.
Ví dụ, khi giải một bài toán toán học, thay vì chỉ yêu cầu kết quả, CoT sẽ hướng dẫn mô hình trình bày từng bước tính toán, giúp mô hình đạt được kết quả chính xác hơn và cung cấp lời giải có thể giải thích được.
Các phương pháp CoT phổ biến bao gồm:
- Zero-shot CoT: Sử dụng câu nhắc như "Hãy suy nghĩ từng bước" mà không cần ví dụ
- Few-shot CoT: Cung cấp một số ví dụ về cách lập luận từng bước
- Self-consistency CoT: Tạo ra nhiều chuỗi lập luận và chọn kết quả phổ biến nhất
3. Multimodal Chain-of-Thought (MCoT) Prompting
3.1. Định nghĩa và khái niệm
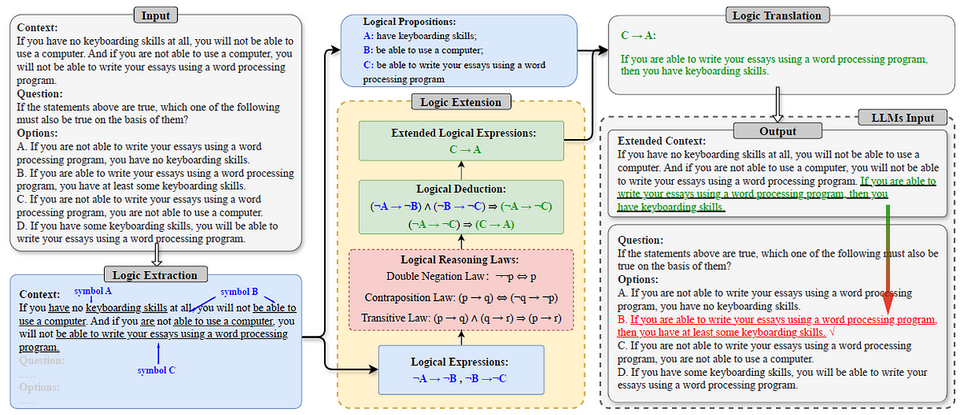
Multimodal Chain-of-Thought (MCoT) Prompting mở rộng khái niệm CoT truyền thống bằng cách kết hợp thông tin từ nhiều phương thức dữ liệu khác nhau, đặc biệt là văn bản và hình ảnh. Theo nghiên cứu của Zhang và cộng sự (2023), MCoT được định nghĩa là một khuôn khổ hai giai đoạn tách biệt quá trình tạo lập luận và suy luận câu trả lời.
Cụ thể, MCoT tích hợp các đặc trưng từ phương thức thị giác (hình ảnh) và ngôn ngữ (văn bản) vào một quy trình hai giai đoạn:
- Giai đoạn tạo lập luận (Rationale Generation): Mô hình tạo ra các bước lập luận trung gian dựa trên thông tin từ cả văn bản và hình ảnh.
- Giai đoạn suy luận câu trả lời (Answer Inference): Mô hình sử dụng các lập luận đã tạo ra để đưa ra câu trả lời cuối cùng.
3.2. Kiến trúc và phương pháp
Theo nghiên cứu của Zhang và cộng sự (2023), kiến trúc MCoT điển hình bao gồm:
- Mô-đun mã hóa hình ảnh (Image Encoder): Trích xuất đặc trưng từ hình ảnh đầu vào, thường sử dụng các mô hình như CLIP, ResNet hoặc Vision Transformer.
- Mô-đun mã hóa văn bản (Text Encoder): Xử lý thông tin văn bản đầu vào, thường là một mô hình ngôn ngữ lớn.
- Mô-đun tích hợp đa phương thức (Multimodal Fusion Module): Kết hợp đặc trưng từ cả hai phương thức để tạo ra biểu diễn đa phương thức.
- Mô-đun tạo lập luận (Rationale Generator): Tạo ra các bước lập luận trung gian dựa trên biểu diễn đa phương thức.
- Mô-đun suy luận câu trả lời (Answer Inferencer): Sử dụng lập luận đã tạo để đưa ra câu trả lời cuối cùng.
Các phương pháp triển khai MCoT có thể được phân loại thành:
- Phương pháp dựa trên học trong ngữ cảnh (In-context Learning): Sử dụng các ví dụ đa phương thức để hướng dẫn mô hình thực hiện lập luận.
- Phương pháp dựa trên tinh chỉnh (Fine-tuning): Huấn luyện mô hình đa phương thức để thực hiện lập luận CoT.
- Phương pháp kết hợp (Hybrid Approaches): Kết hợp cả hai phương pháp trên.
4. Compositional Chain-of-Thought (CCoT)
Một biến thể quan trọng của MCoT là Compositional Chain-of-Thought (CCoT), được giới thiệu bởi Mitra và cộng sự tại hội nghị CVPR 2024. CCoT là một phương pháp zero-shot Chain-of-Thought mới sử dụng biểu diễn đồ thị cảnh (Scene Graph) để trích xuất kiến thức tổ hợp từ các mô hình đa phương thức lớn.
CCoT giải quyết một thách thức quan trọng của các mô hình đa phương thức: khả năng hiểu và lập luận về các mối quan hệ tổ hợp giữa các đối tượng trong hình ảnh. Phương pháp này không chỉ cải thiện hiệu suất của các mô hình đa phương thức trên các bài toán tổ hợp mà còn trên các bài toán đa phương thức tổng quát.
Quy trình của CCoT bao gồm:
- Tạo biểu diễn đồ thị cảnh từ hình ảnh đầu vào
- Sử dụng biểu diễn này để hướng dẫn mô hình thực hiện lập luận từng bước
- Kết hợp thông tin từ đồ thị cảnh và văn bản để đưa ra câu trả lời cuối cùng
5. Ứng dụng của Multimodal CoT Prompting
MCoT đã được ứng dụng thành công trong nhiều lĩnh vực:
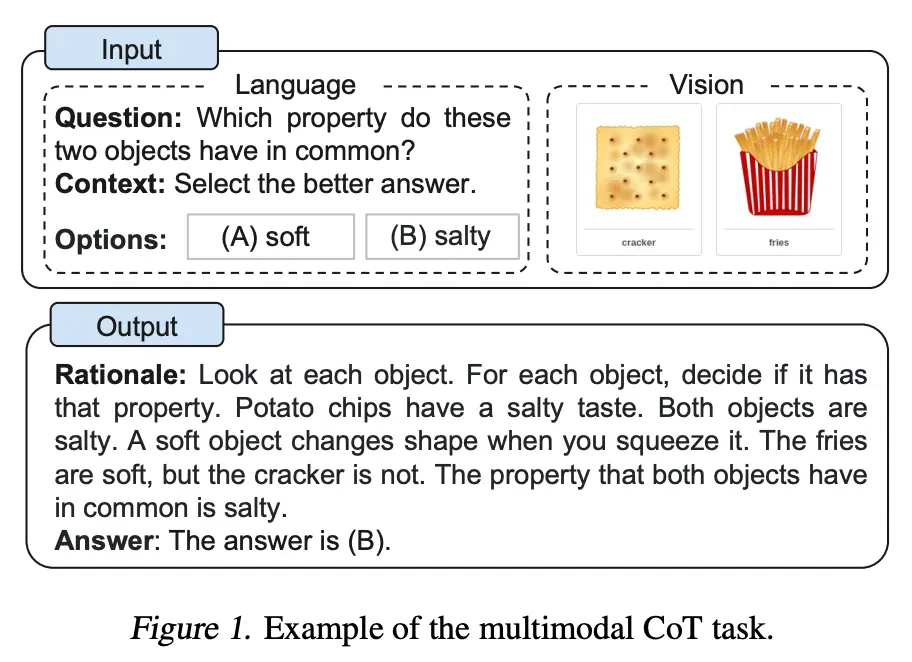
5.1. Trả lời câu hỏi dựa trên hình ảnh (Visual Question Answering - VQA)
MCoT giúp cải thiện đáng kể hiệu suất của các mô hình trong các bài toán VQA phức tạp, đặc biệt là những bài toán đòi hỏi lập luận nhiều bước. Ví dụ, khi được hỏi về số lượng đối tượng trong một hình ảnh phức tạp, MCoT có thể hướng dẫn mô hình xác định từng đối tượng trước khi đếm tổng số.
5.2. Lập luận toán học dựa trên hình ảnh
Trong các bài toán toán học có hình ảnh minh họa, MCoT giúp mô hình kết hợp thông tin từ cả văn bản và hình ảnh để giải quyết bài toán. Ví dụ, khi giải một bài toán hình học, MCoT có thể hướng dẫn mô hình xác định các thành phần trong hình, áp dụng các công thức phù hợp và tính toán kết quả.
5.3. Tạo ẩn dụ từ hình ảnh
Một ứng dụng thú vị của MCoT là tạo ra các biểu thức ẩn dụ từ hình ảnh không ẩn dụ. Nghiên cứu gần đây đã sử dụng mô hình LLaVA 1.5 và phương pháp MCoT hai bước để tạo ra các ẩn dụ ngôn ngữ từ hình ảnh thông thường.
5.4. Lập luận khoa học
MCoT đã được ứng dụng trong việc trả lời các câu hỏi khoa học phức tạp, nơi mô hình cần kết hợp kiến thức từ văn bản và hình ảnh để đưa ra lời giải thích khoa học chính xác.
6. Thách thức và hướng phát triển
Mặc dù MCoT đã đạt được những tiến bộ đáng kể, vẫn còn nhiều thách thức cần giải quyết:
6.1. Thách thức
- Tích hợp đa phương thức hiệu quả: Việc kết hợp thông tin từ các phương thức khác nhau một cách hiệu quả vẫn là một thách thức lớn.
- Khả năng mở rộng: Mở rộng MCoT sang các phương thức khác ngoài văn bản và hình ảnh, như âm thanh, video, dữ liệu 3D...
- Hiệu quả tính toán: Các mô hình MCoT thường đòi hỏi tài nguyên tính toán lớn, đặc biệt khi xử lý nhiều phương thức dữ liệu.
- Đánh giá hiệu suất: Thiếu các tiêu chuẩn đánh giá thống nhất cho lập luận đa phương thức.
6.2. Hướng phát triển
- Mở rộng sang nhiều phương thức hơn: Phát triển các phương pháp MCoT cho video, âm thanh, dữ liệu 3D và các phương thức khác.
- Cải thiện khả năng lập luận tổ hợp: Tăng cường khả năng hiểu và lập luận về các mối quan hệ tổ hợp giữa các đối tượng.
- Phát triển các phương pháp đánh giá: Xây dựng các tiêu chuẩn đánh giá toàn diện cho lập luận đa phương thức.
- Giảm yêu cầu tài nguyên: Phát triển các phương pháp MCoT hiệu quả hơn về mặt tính toán.
7. Kết luận
Multimodal Chain-of-Thought (MCoT) Prompting đại diện cho một bước tiến quan trọng trong việc nâng cao khả năng lập luận của các mô hình ngôn ngữ lớn trong bối cảnh đa phương thức. Bằng cách kết hợp thông tin từ nhiều phương thức dữ liệu khác nhau và hướng dẫn mô hình thực hiện lập luận từng bước, MCoT giúp các mô hình giải quyết các bài toán phức tạp một cách hiệu quả hơn.
Với sự phát triển nhanh chóng của các mô hình ngôn ngữ lớn đa phương thức (MLLMs), MCoT hứa hẹn sẽ tiếp tục đóng vai trò quan trọng trong việc nâng cao khả năng lập luận và giải quyết vấn đề của các mô hình này. Các nghiên cứu trong tương lai sẽ tập trung vào việc mở rộng MCoT sang nhiều phương thức hơn, cải thiện khả năng lập luận tổ hợp và phát triển các phương pháp đánh giá toàn diện.
Tài liệu tham khảo
- Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., & Smola, A. (2023). Multimodal Chain-of-Thought Reasoning in Language Models. arXiv:2302.00923. https://arxiv.org/abs/2302.00923
- Mitra, C., Ren, M., Sharma, P., & Batra, D. (2024). Compositional Chain-of-Thought Prompting for Large Multimodal Models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024). https://openaccess.thecvf.com/content/CVPR2024/papers/Mitra_Compositional_Chain-of-Thought_Prompting_for_Large_Multimodal_Models_CVPR_2024_paper.pdf
- Wang, Y., Zhao, Z., Jiang, Z., Ren, X., Zhao, R., Zhou, J., & Yin, H. (2024). Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey. arXiv:2503.12605. https://arxiv.org/abs/2503.12605
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems, 35, 24824-24837.
- Luo, X., Huang, Z., Boularias, A., & Bekris, K. (2024). PKRD-CoT: A Unified Chain-of-thought Prompting for Multi-modal Perception-based Knowledge Reasoning and Decision-making. arXiv:2412.02025. https://arxiv.org/abs/2412.02025