Kỹ Thuật Dense Retrieval Trong RAG (Retrieval-Augmented Generation)
Dense Retrieval là phương pháp truy xuất thông tin dựa trên biểu diễn vector mật độ cao, đóng vai trò quan trọng trong hệ thống RAG hiện đại, giúp nâng cao khả năng hiểu ngữ nghĩa và truy xuất thông tin chính xác cho các mô hình ngôn ngữ lớn.
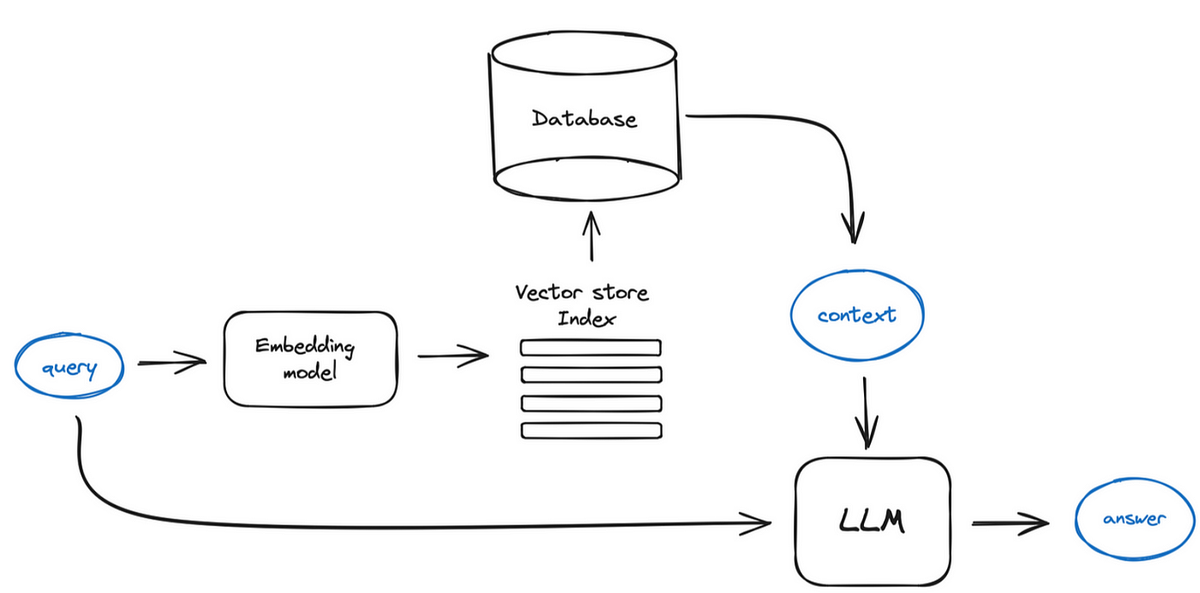
1. Giới thiệu về RAG và vai trò của Dense Retrieval
Retrieval-Augmented Generation (RAG) là một kỹ thuật tiên tiến trong lĩnh vực xử lý ngôn ngữ tự nhiên, kết hợp hai quá trình chính: truy xuất thông tin (retrieval) và tạo văn bản (generation). Phương pháp này được giới thiệu lần đầu trong nghiên cứu của Lewis và cộng sự (2020) với mục tiêu nâng cao khả năng của các mô hình ngôn ngữ lớn (LLM) trong việc xử lý các tác vụ đòi hỏi kiến thức chuyên sâu.
Trong hệ thống RAG, Dense Retrieval đóng vai trò then chốt ở bước truy xuất thông tin. Khác với phương pháp truy xuất thông tin truyền thống (Sparse Retrieval), Dense Retrieval sử dụng các biểu diễn vector mật độ cao (dense vectors) để nắm bắt ngữ nghĩa sâu của văn bản, giúp hệ thống hiểu được ý định và ngữ cảnh của câu hỏi, từ đó truy xuất thông tin liên quan chính xác hơn.
2. Cơ chế hoạt động của Dense Retrieval
2.1. Nguyên lý cơ bản
Dense Retrieval hoạt động dựa trên việc biến đổi cả câu truy vấn (query) và các đoạn văn bản (passages) thành các vector nhúng (embeddings) trong không gian vector nhiều chiều. Các vector này là "mật độ cao" (dense) vì chúng có giá trị ở hầu hết các chiều, khác với biểu diễn thưa (sparse) truyền thống như TF-IDF chỉ có giá trị khác không ở một số ít chiều.
Quá trình Dense Retrieval trong RAG thường bao gồm các bước sau:
- Tiền xử lý dữ liệu: Chia nhỏ tài liệu thành các đoạn văn bản có kích thước phù hợp.
- Tạo embedding: Sử dụng mô hình embedding để chuyển đổi các đoạn văn bản thành vector nhúng.
- Lưu trữ vector: Lưu trữ các vector trong cơ sở dữ liệu vector (vector database) như FAISS, Pinecone, hoặc Milvus.
- Truy vấn: Khi nhận được câu hỏi, chuyển đổi câu hỏi thành vector nhúng và tìm kiếm các vector gần nhất trong cơ sở dữ liệu.
- Truy xuất: Lấy ra các đoạn văn bản tương ứng với các vector gần nhất để cung cấp cho bước tạo văn bản.
2.2. Mô hình Dense Retrieval phổ biến
Một trong những mô hình Dense Retrieval được sử dụng rộng rãi nhất là DPR (Dense Passage Retrieval), được giới thiệu bởi Karpukhin và cộng sự (2020). DPR sử dụng hai bộ mã hóa BERT riêng biệt: một cho câu truy vấn và một cho đoạn văn bản. Mô hình được huấn luyện để tối đa hóa độ tương đồng giữa câu truy vấn và đoạn văn bản liên quan, đồng thời giảm thiểu độ tương đồng với các đoạn văn bản không liên quan.
Các mô hình Dense Retrieval tiên tiến khác bao gồm:
- ANCE (Approximate Nearest Neighbor Negative Contrastive Estimation): Cải thiện quá trình chọn mẫu âm trong huấn luyện.
- ColBERT: Sử dụng cơ chế so khớp mức từ (token-level matching) để nâng cao độ chính xác.
- E5 và BGE: Các mô hình embedding hiện đại được tối ưu hóa cho nhiều ngôn ngữ và tác vụ khác nhau.
3. So sánh Dense Retrieval với Sparse Retrieval
3.1. Đặc điểm của Sparse Retrieval
Sparse Retrieval là phương pháp truy xuất thông tin truyền thống, sử dụng biểu diễn vector thưa dựa trên từ vựng. Các kỹ thuật phổ biến bao gồm:
- BM25: Cải tiến của TF-IDF, tính toán điểm số dựa trên tần suất xuất hiện của từ và độ dài tài liệu.
- TF-IDF (Term Frequency-Inverse Document Frequency): Đánh giá tầm quan trọng của từ dựa trên tần suất xuất hiện trong tài liệu và trong toàn bộ kho dữ liệu.
Ưu điểm chính của Sparse Retrieval:
- Hiệu quả tính toán cao nhờ sử dụng chỉ mục ngược (inverted index).
- Khả năng xử lý từ khóa chính xác và thuật ngữ chuyên ngành tốt.
- Không đòi hỏi dữ liệu huấn luyện lớn.
- Dễ dàng giải thích kết quả truy xuất.
3.2. Ưu điểm của Dense Retrieval
So với Sparse Retrieval, Dense Retrieval có những ưu điểm nổi bật sau:
- Hiểu ngữ nghĩa tốt hơn: Nắm bắt được mối quan hệ ngữ nghĩa giữa các từ và cụm từ, ngay cả khi chúng không chia sẻ từ khóa chung.
- Xử lý đồng nghĩa và đa nghĩa: Có khả năng hiểu các từ đồng nghĩa và phân biệt các từ đa nghĩa dựa vào ngữ cảnh.
- Hiệu quả với câu truy vấn phức tạp: Hoạt động tốt với câu hỏi dài, hội thoại và ngôn ngữ tự nhiên.
- Khả năng khái quát hóa: Có thể truy xuất thông tin liên quan ngay cả khi từ ngữ sử dụng khác với dữ liệu gốc.
3.3. Hạn chế của Dense Retrieval
Mặc dù có nhiều ưu điểm, Dense Retrieval vẫn tồn tại một số hạn chế:
- Chi phí tính toán cao: Việc tạo và so sánh vector mật độ cao đòi hỏi nhiều tài nguyên tính toán hơn.
- Phụ thuộc vào dữ liệu huấn luyện: Hiệu suất phụ thuộc vào chất lượng và số lượng dữ liệu huấn luyện.
- Khó khăn với thuật ngữ hiếm: Có thể gặp khó khăn khi xử lý các thuật ngữ chuyên ngành hoặc từ hiếm không xuất hiện trong dữ liệu huấn luyện.
- Yêu cầu lưu trữ lớn: Các vector mật độ cao chiếm nhiều không gian lưu trữ hơn so với biểu diễn thưa.
4. Kỹ thuật nâng cao trong Dense Retrieval cho RAG
4.1. Hybrid Retrieval
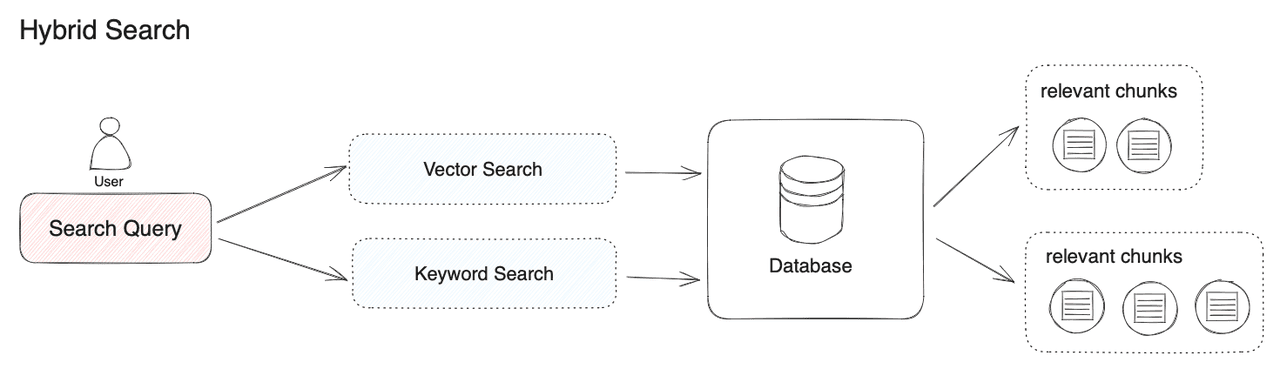
Để khắc phục hạn chế của cả Dense Retrieval và Sparse Retrieval, nhiều hệ thống RAG hiện đại sử dụng phương pháp Hybrid Retrieval, kết hợp ưu điểm của cả hai phương pháp:
- Kết hợp song song: Thực hiện cả truy vấn dense và sparse, sau đó kết hợp kết quả dựa trên điểm số.
- Truy xuất theo tầng (Cascading Retrieval): Sử dụng phương pháp sparse để lọc nhanh một tập hợp lớn tài liệu, sau đó áp dụng dense retrieval để tinh chỉnh kết quả.
Theo nghiên cứu của AWS, việc kết hợp vector sparse và dense trong OpenSearch Service đã cải thiện đáng kể hiệu suất truy xuất thông tin cho các hệ thống RAG.
4.2. Contrastive Learning
Contrastive Learning là kỹ thuật huấn luyện quan trọng trong Dense Retrieval, giúp mô hình học cách phân biệt giữa các cặp query-passage liên quan và không liên quan:
- In-batch Negatives: Sử dụng các mẫu âm từ cùng một batch để tăng hiệu quả huấn luyện.
- Hard Negative Mining: Chọn lọc các mẫu âm "khó" (gần với mẫu dương về mặt ngữ nghĩa nhưng không liên quan) để cải thiện khả năng phân biệt của mô hình.
4.3. Reranking
Reranking là bước bổ sung sau khi truy xuất ban đầu, nhằm sắp xếp lại các kết quả để tăng độ chính xác:
- Cross-Encoder: Sử dụng mô hình cross-encoder để đánh giá lại độ liên quan giữa câu truy vấn và các đoạn văn bản đã truy xuất.
- Tensor Reranker: Sử dụng các mô hình tensor để nắm bắt mối quan hệ phức tạp giữa câu truy vấn và đoạn văn bản.
5. Ứng dụng Dense Retrieval trong các hệ thống RAG thực tế
5.1. Cải thiện chất lượng phản hồi của LLM
Dense Retrieval giúp cải thiện đáng kể chất lượng phản hồi của các mô hình ngôn ngữ lớn trong hệ thống RAG:
- Giảm thiểu hiện tượng ảo tưởng (hallucination): Cung cấp thông tin chính xác từ nguồn đáng tin cậy.
- Cập nhật kiến thức: Cho phép mô hình truy cập thông tin mới nhất mà không cần tái huấn luyện.
- Tăng độ tin cậy: Hỗ trợ trích dẫn nguồn thông tin, tăng tính minh bạch và đáng tin cậy.
5.2. Tối ưu hóa Dense Retrieval cho RAG
Để tối ưu hóa Dense Retrieval trong hệ thống RAG, các kỹ thuật sau thường được áp dụng:
- Chunking thông minh: Phân chia tài liệu thành các đoạn có kích thước và nội dung phù hợp.
- Tối ưu hóa mô hình embedding: Lựa chọn hoặc tinh chỉnh mô hình embedding phù hợp với miền ứng dụng.
- Approximate Nearest Neighbor (ANN): Sử dụng các thuật toán tìm kiếm lân cận gần đúng để tăng tốc độ truy vấn.
- Metadata filtering: Kết hợp lọc metadata với tìm kiếm vector để thu hẹp phạm vi tìm kiếm.
6. Thách thức và hướng phát triển trong tương lai
6.1. Thách thức hiện tại
Dense Retrieval trong RAG vẫn đối mặt với một số thách thức:
- Hiệu suất với dữ liệu đa ngôn ngữ: Cần cải thiện khả năng xử lý và hiểu ngữ nghĩa trong nhiều ngôn ngữ khác nhau.
- Khả năng mở rộng: Đối với kho dữ liệu lớn, việc tìm kiếm vector hiệu quả vẫn là thách thức.
- Cân bằng giữa độ chính xác và hiệu suất: Tìm điểm cân bằng giữa chất lượng truy xuất và tốc độ xử lý.
- Đánh giá hiệu quả: Xây dựng các phương pháp đánh giá toàn diện cho hệ thống RAG.
6.2. Hướng phát triển trong tương lai
Các hướng nghiên cứu và phát triển đầy hứa hẹn cho Dense Retrieval trong RAG:
- Multi-modal Retrieval: Mở rộng khả năng truy xuất sang dữ liệu đa phương tiện như hình ảnh, âm thanh và video.
- Retrieval với ít dữ liệu huấn luyện: Phát triển các phương pháp hiệu quả với dữ liệu huấn luyện hạn chế.
- Retrieval có khả năng giải thích: Tăng cường khả năng giải thích lý do tại sao một đoạn văn bản được truy xuất.
- Retrieval động (Dynamic Retrieval): Phát triển các phương pháp truy xuất thông minh, có thể điều chỉnh chiến lược dựa trên ngữ cảnh và loại truy vấn.
7. Kết luận
Dense Retrieval đã trở thành một thành phần không thể thiếu trong các hệ thống RAG hiện đại, mang lại khả năng hiểu ngữ nghĩa sâu sắc và truy xuất thông tin chính xác. Mặc dù vẫn tồn tại một số thách thức, nhưng với sự phát triển không ngừng của các kỹ thuật mới, Dense Retrieval đang ngày càng được cải thiện và mở rộng khả năng ứng dụng.
Việc kết hợp Dense Retrieval với các phương pháp khác như Sparse Retrieval và Reranking trong một hệ thống hybrid đang trở thành xu hướng chủ đạo, giúp tận dụng ưu điểm của từng phương pháp và khắc phục hạn chế của chúng. Trong tương lai, Dense Retrieval sẽ tiếp tục đóng vai trò quan trọng trong việc nâng cao khả năng của các hệ thống AI trong việc truy cập, hiểu và sử dụng thông tin một cách hiệu quả.
Tài liệu tham khảo
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., ... & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401. https://arxiv.org/abs/2005.11401
- Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., ... & Yih, W. T. (2020). Dense Passage Retrieval for Open-Domain Question Answering. arXiv:2004.04906.
- Khobnia, A. (2023). Deep Learning in Information Retrieval. Part II: Dense Retrieval. Medium. https://medium.com/@aikho/deep-learning-in-information-retrieval-part-ii-dense-retrieval-1f9fecb47de9
- Palvel, S. (2023). Embedding Technologies in RAG: Vector Embeddings and Semantic Search Techniques. Medium. https://subashpalvel.medium.com/embedding-technologies-in-rag-vector-embeddings-and-semantic-search-techniques-dddc3b6e78f0
- AWS. (2023). Integrate sparse and dense vectors to enhance knowledge retrieval in RAG using Amazon OpenSearch Service. Amazon Web Services. https://aws.amazon.com/blogs/big-data/integrate-sparse-and-dense-vectors-to-enhance-knowledge-retrieval-in-rag-using-amazon-opensearch-service
- Tunkelang, D. (2023). Sparse and Dense Representations. Medium. https://dtunkelang.medium.com/sparse-and-dense-representations-f8c94f1e28e8
- Milvus. (2023). What is the difference between sparse and dense retrieval? https://milvus.io/ai-quick-reference/what-is-the-difference-between-sparse-and-dense-retrieval
- NVIDIA. (2023). What Is Retrieval-Augmented Generation aka RAG. NVIDIA Blogs. https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation
- Galileo AI. (2024). Mastering RAG: How to Select an Embedding Model. https://galileo.ai/blog/mastering-rag-how-to-select-an-embedding-model
- Khan, N. (2024). Retrieval Techniques - Sparse, Dense, and Hybrid Representations. LinkedIn. https://linkedin.com/pulse/retrieval-techniques-sparse-dense-hybrid-najeeb-khan-ph-d--wmtpc