Kỹ thuật Chunk Engineering trong RAG: Phương pháp tiếp cận toàn diện
Bài viết này phân tích chi tiết về kỹ thuật Chunk Engineering trong hệ thống RAG, giúp tối ưu hóa quá trình truy xuất thông tin và nâng cao chất lượng phản hồi của mô hình ngôn ngữ lớn thông qua các phương pháp phân đoạn dữ liệu hiệu quả.
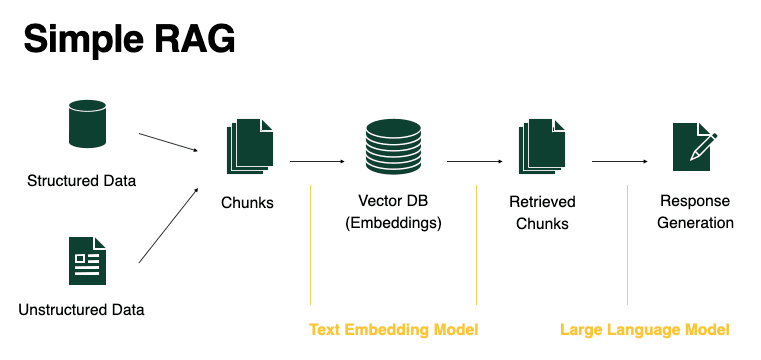
1. Giới thiệu về RAG và tầm quan trọng của Chunk Engineering
Retrieval Augmented Generation (RAG) là một kỹ thuật nâng cao khả năng của các mô hình ngôn ngữ lớn (LLM) bằng cách tích hợp thông tin từ nguồn dữ liệu bên ngoài. Thay vì chỉ dựa vào kiến thức đã được học trong quá trình huấn luyện, RAG cho phép LLM truy xuất thông tin liên quan từ cơ sở dữ liệu bên ngoài để tạo ra câu trả lời chính xác và cập nhật hơn.
Chunk Engineering, hay kỹ thuật phân đoạn dữ liệu, đóng vai trò then chốt trong quy trình RAG. Đây là quá trình chia nhỏ tài liệu thành các đoạn (chunks) có kích thước phù hợp để lưu trữ trong cơ sở dữ liệu vector và truy xuất hiệu quả. Cách thức phân đoạn dữ liệu ảnh hưởng trực tiếp đến:
- Chất lượng kết quả truy xuất
- Khả năng bảo toàn ngữ cảnh
- Hiệu suất của hệ thống RAG
- Độ chính xác của câu trả lời từ LLM
Theo nghiên cứu gần đây từ các chuyên gia trong lĩnh vực, việc lựa chọn chiến lược phân đoạn phù hợp có thể cải thiện hiệu suất RAG lên đến 30-40% so với phương pháp phân đoạn đơn giản.
2. Các phương pháp Chunk Engineering cơ bản
2.1. Phân đoạn dựa trên kích thước cố định (Fixed-size Chunking)
Đây là phương pháp đơn giản nhất, chia tài liệu thành các đoạn có số lượng token hoặc ký tự cố định.
Ưu điểm:
- Dễ triển khai
- Đảm bảo kích thước đồng nhất giữa các đoạn
Nhược điểm:
- Có thể cắt đứt câu, đoạn văn hoặc ý tưởng hoàn chỉnh
- Không tôn trọng cấu trúc ngữ nghĩa của văn bản
# Ví dụ về phân đoạn dựa trên kích thước cố định
def fixed_size_chunking(text, chunk_size=500, overlap=50):
chunks = []
start = 0
while start < len(text):
end = min(start + chunk_size, len(text))
chunks.append(text[start:end])
start = end - overlap
return chunks
2.2. Phân đoạn dựa trên ranh giới văn bản (Boundary-based Chunking)
Phương pháp này chia tài liệu tại các ranh giới tự nhiên như đoạn văn, câu, hoặc tiêu đề.
Ưu điểm:
- Bảo toàn cấu trúc tự nhiên của văn bản
- Giữ nguyên tính liên kết của thông tin
Nhược điểm:
- Có thể tạo ra các đoạn có kích thước không đồng đều
- Khó xử lý với tài liệu có cấu trúc phức tạp
# Ví dụ về phân đoạn dựa trên ranh giới đoạn văn
def paragraph_chunking(text):
return [p.strip() for p in text.split('\n\n') if p.strip()]
2.3. Phân đoạn dựa trên token (Token-based Chunking)
Phương pháp này chia tài liệu dựa trên số lượng token (đơn vị xử lý của LLM), thay vì số ký tự.
Ưu điểm:
- Phù hợp với cách LLM xử lý văn bản
- Kiểm soát tốt hơn kích thước đầu vào cho mô hình
Nhược điểm:
- Vẫn có thể cắt đứt ý tưởng hoàn chỉnh
- Yêu cầu tokenizer phù hợp với mô hình đang sử dụng
3. Kỹ thuật Chunk Engineering nâng cao
3.1. Phân đoạn đệ quy (Recursive Chunking)
Phương pháp này chia tài liệu theo cách phân cấp và lặp lại, sử dụng một tập hợp các dấu phân cách.
Quy trình:
- Bắt đầu với dấu phân cách mức cao nhất (ví dụ: "\n\n" cho đoạn văn)
- Nếu đoạn vẫn quá lớn, tiếp tục chia nhỏ bằng dấu phân cách mức thấp hơn (ví dụ: "\n" cho dòng)
- Tiếp tục quá trình cho đến khi đạt được kích thước đoạn mong muốn
Ưu điểm:
- Thích ứng với cấu trúc tài liệu
- Bảo toàn tốt hơn ngữ cảnh và ý nghĩa
# Ví dụ về phân đoạn đệ quy
def recursive_chunking(text, chunk_size=500, separators=["\n\n", "\n", ". ", ", "]):
if len(text) <= chunk_size:
return [text]
for separator in separators:
if separator in text:
chunks = []
segments = text.split(separator)
current_chunk = segments[0]
for segment in segments[1:]:
if len(current_chunk) + len(separator) + len(segment) <= chunk_size:
current_chunk += separator + segment
else:
chunks.append(current_chunk)
current_chunk = segment
if current_chunk:
chunks.append(current_chunk)
# Nếu vẫn có đoạn quá lớn, tiếp tục phân chia đệ quy
result = []
for chunk in chunks:
if len(chunk) > chunk_size and len(separators) > 1:
result.extend(recursive_chunking(chunk, chunk_size, separators[1:]))
else:
result.append(chunk)
return result
# Nếu không có dấu phân cách nào, trả về phân đoạn dựa trên kích thước
return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]
3.2. Phân đoạn ngữ nghĩa (Semantic Chunking)
Phương pháp này phân chia tài liệu dựa trên nội dung ngữ nghĩa, đảm bảo mỗi đoạn chứa thông tin liên quan đến nhau.
Quy trình:
- Sử dụng mô hình nhúng (embedding) để biểu diễn văn bản
- Phân tích sự tương đồng ngữ nghĩa giữa các phần của tài liệu
- Nhóm các phần có nội dung liên quan thành một đoạn
Ưu điểm:
- Bảo toàn tối đa ngữ cảnh và ý nghĩa
- Cải thiện đáng kể chất lượng truy xuất
Nhược điểm:
- Tốn kém về mặt tính toán
- Phức tạp trong triển khai
# Ví dụ đơn giản về phân đoạn ngữ nghĩa
def semantic_chunking(text, embedding_model, max_chunk_size=500, similarity_threshold=0.7):
# Chia thành các câu
sentences = [s.strip() for s in text.split('.') if s.strip()]
# Tính toán embedding cho mỗi câu
embeddings = [embedding_model.encode(sentence) for sentence in sentences]
chunks = []
current_chunk = sentences[0]
current_sentences = [sentences[0]]
for i in range(1, len(sentences)):
# Tính toán độ tương đồng với đoạn hiện tại
avg_similarity = np.mean([cosine_similarity(embeddings[i], embeddings[j])
for j in range(i-len(current_sentences), i)])
if (avg_similarity > similarity_threshold and
len(current_chunk) + len(sentences[i]) <= max_chunk_size):
current_chunk += ". " + sentences[i]
current_sentences.append(sentences[i])
else:
chunks.append(current_chunk)
current_chunk = sentences[i]
current_sentences = [sentences[i]]
if current_chunk:
chunks.append(current_chunk)
return chunks
3.3. Phân đoạn lai (Hybrid Chunking)
Kết hợp nhiều phương pháp phân đoạn để tận dụng ưu điểm của từng phương pháp.
Ví dụ về phương pháp lai:
- Sử dụng phân đoạn dựa trên cấu trúc cho tài liệu có định dạng rõ ràng (như HTML, PDF)
- Áp dụng phân đoạn ngữ nghĩa cho nội dung văn bản thuần
- Kết hợp với phân đoạn đệ quy để kiểm soát kích thước
Ưu điểm:
- Linh hoạt với nhiều loại tài liệu
- Cân bằng giữa chất lượng và hiệu suất
3.4. Phân đoạn Small2Big
Phương pháp này tạo ra cả đoạn nhỏ và đoạn lớn, sử dụng đoạn nhỏ để truy xuất ban đầu và đoạn lớn để cung cấp ngữ cảnh đầy đủ.
Quy trình:
- Chia tài liệu thành các đoạn nhỏ (ví dụ: 100-200 token)
- Lưu trữ thông tin về đoạn lớn (ví dụ: đoạn văn hoặc phần) chứa đoạn nhỏ
- Khi truy xuất, sử dụng đoạn nhỏ để tìm kiếm, nhưng trả về đoạn lớn tương ứng
Ưu điểm:
- Cải thiện độ chính xác của truy xuất
- Cung cấp ngữ cảnh đầy đủ hơn cho LLM
4. Chiến lược tối ưu hóa Chunk Engineering cho các loại tài liệu khác nhau
4.1. Tài liệu văn bản dài
Chiến lược khuyến nghị:
- Phân đoạn đệ quy với nhiều mức dấu phân cách
- Kết hợp với Small2Big để bảo toàn ngữ cảnh
- Sử dụng kỹ thuật cửa sổ trượt (sliding window) với độ chồng lấp 10-20%
4.2. Tài liệu có cấu trúc (PDF, HTML)
Chiến lược khuyến nghị:
- Phân đoạn dựa trên cấu trúc tài liệu (tiêu đề, đoạn văn, bảng)
- Bảo toàn thông tin bố cục và định dạng
- Xử lý đặc biệt cho bảng, biểu đồ và hình ảnh
4.3. Tài liệu kỹ thuật và khoa học
Chiến lược khuyến nghị:
- Phân đoạn ngữ nghĩa để bảo toàn khái niệm phức tạp
- Giữ nguyên công thức, phương trình và tham chiếu
- Tạo đoạn đặc biệt cho phần tóm tắt, kết luận và tài liệu tham khảo
4.4. Hội thoại và trao đổi email
Chiến lược khuyến nghị:
- Phân đoạn theo người tham gia hoặc chủ đề
- Bảo toàn chuỗi hội thoại
- Sử dụng kỹ thuật phân đoạn dựa trên thời gian cho các cuộc trò chuyện dài
5. Đánh giá hiệu quả của Chunk Engineering
5.1. Các chỉ số đánh giá
- Độ chính xác truy xuất (Retrieval Accuracy): Tỷ lệ đoạn liên quan được truy xuất thành công
- Độ bao phủ ngữ cảnh (Context Coverage): Mức độ bảo toàn ngữ cảnh trong các đoạn
- Độ chính xác câu trả lời (Answer Accuracy): Chất lượng câu trả lời từ LLM dựa trên đoạn được truy xuất
- Hiệu suất hệ thống (System Performance): Thời gian và tài nguyên cần thiết cho quá trình phân đoạn và truy xuất
5.2. Phương pháp kiểm thử
# Ví dụ về đánh giá hiệu quả phân đoạn
def evaluate_chunking_strategy(documents, chunking_function, queries, ground_truth):
chunks = []
for doc in documents:
chunks.extend(chunking_function(doc))
# Tạo cơ sở dữ liệu vector
vector_db = create_vector_db(chunks)
# Đánh giá truy xuất
retrieval_scores = []
for query, relevant_info in zip(queries, ground_truth):
retrieved_chunks = vector_db.search(query, top_k=5)
score = calculate_relevance(retrieved_chunks, relevant_info)
retrieval_scores.append(score)
return {
"avg_retrieval_score": np.mean(retrieval_scores),
"chunk_count": len(chunks),
"avg_chunk_size": np.mean([len(chunk) for chunk in chunks])
}
6. Các xu hướng và nghiên cứu mới trong Chunk Engineering
6.1. Phân đoạn thích ứng (Adaptive Chunking)
Phương pháp này tự động điều chỉnh chiến lược phân đoạn dựa trên nội dung và cấu trúc của tài liệu.
Đặc điểm:
- Sử dụng học máy để xác định ranh giới tối ưu
- Điều chỉnh kích thước đoạn dựa trên độ phức tạp của nội dung
- Tự động chọn phương pháp phân đoạn phù hợp nhất
6.2. Phân đoạn đa cấp (Multi-level Chunking)
Tạo ra nhiều phiên bản phân đoạn của cùng một tài liệu ở các mức độ chi tiết khác nhau.
Quy trình:
- Tạo đoạn cấp cao (ví dụ: chương, phần)
- Tạo đoạn cấp trung (ví dụ: đoạn văn)
- Tạo đoạn cấp thấp (ví dụ: câu, cụm từ)
- Lưu trữ mối quan hệ phân cấp giữa các đoạn
Ưu điểm:
- Cho phép truy xuất ở nhiều mức độ chi tiết
- Cải thiện khả năng mở rộng quy mô của hệ thống RAG
6.3. Phân đoạn có nhận thức về nhiệm vụ (Task-aware Chunking)
Điều chỉnh chiến lược phân đoạn dựa trên loại nhiệm vụ hoặc truy vấn dự kiến.
Ví dụ:
- Đối với truy vấn tìm kiếm sự kiện: sử dụng đoạn nhỏ, tập trung vào thông tin cụ thể
- Đối với truy vấn tổng hợp: sử dụng đoạn lớn hơn, bao gồm nhiều ngữ cảnh
7. Thực tiễn tốt nhất và hướng dẫn triển khai
7.1. Quy trình lựa chọn chiến lược phân đoạn
- Phân tích tài liệu: Xác định loại, cấu trúc và đặc điểm của tài liệu
- Xác định yêu cầu: Hiểu rõ loại truy vấn và mục tiêu của hệ thống RAG
- Thử nghiệm: Kiểm thử nhiều chiến lược phân đoạn với tập dữ liệu đại diện
- Đánh giá: So sánh hiệu suất dựa trên các chỉ số đã xác định
- Tinh chỉnh: Điều chỉnh tham số và kết hợp các phương pháp để tối ưu hóa kết quả
7.2. Cân nhắc kỹ thuật
- Kích thước đoạn tối ưu: Thường từ 200-1000 token tùy thuộc vào ứng dụng
- Độ chồng lấp: 10-20% để đảm bảo không mất thông tin tại ranh giới
- Xử lý trước: Làm sạch và chuẩn hóa văn bản trước khi phân đoạn
- Lưu trữ metadata: Giữ thông tin về nguồn, vị trí và mối quan hệ của đoạn
7.3. Mã nguồn mẫu cho triển khai toàn diện
# Ví dụ về hệ thống phân đoạn toàn diện
class ChunkEngineer:
def __init__(self, embedding_model, default_chunk_size=500, default_overlap=50):
self.embedding_model = embedding_model
self.default_chunk_size = default_chunk_size
self.default_overlap = default_overlap
def analyze_document(self, document):
# Phân tích cấu trúc và nội dung tài liệu
doc_length = len(document)
has_structure = self._detect_structure(document)
complexity = self._estimate_complexity(document)
return {
"length": doc_length,
"has_structure": has_structure,
"complexity": complexity
}
def select_strategy(self, document_analysis):
# Chọn chiến lược phân đoạn dựa trên phân tích
if document_analysis["has_structure"]:
return self.structure_based_chunking
elif document_analysis["complexity"] > 0.7:
return self.semantic_chunking
elif document_analysis["length"] > 10000:
return self.recursive_chunking
else:
return self.fixed_size_chunking
def process_document(self, document):
# Xử lý tài liệu từ đầu đến cuối
analysis = self.analyze_document(document)
chunking_strategy = self.select_strategy(analysis)
# Tiền xử lý
clean_document = self._preprocess(document)
# Phân đoạn
chunks = chunking_strategy(clean_document)
# Thêm metadata
enriched_chunks = self._add_metadata(chunks, document)
return enriched_chunks
# Các phương pháp phân đoạn cụ thể
def fixed_size_chunking(self, text):
# Triển khai phân đoạn kích thước cố định
pass
def structure_based_chunking(self, text):
# Triển khai phân đoạn dựa trên cấu trúc
pass
def recursive_chunking(self, text):
# Triển khai phân đoạn đệ quy
pass
def semantic_chunking(self, text):
# Triển khai phân đoạn ngữ nghĩa
pass
# Các phương pháp hỗ trợ
def _detect_structure(self, document):
# Phát hiện cấu trúc trong tài liệu
pass
def _estimate_complexity(self, document):
# Ước tính độ phức tạp của nội dung
pass
def _preprocess(self, document):
# Tiền xử lý tài liệu
pass
def _add_metadata(self, chunks, original_document):
# Thêm metadata cho các đoạn
pass
8. Nghiên cứu tình huống và bài học kinh nghiệm
8.1. Tình huống 1: Hệ thống hỏi đáp tài liệu pháp lý
Thách thức:
- Tài liệu dài và phức tạp
- Ngôn ngữ chuyên ngành
- Yêu cầu độ chính xác cao
Giải pháp:
- Sử dụng phân đoạn lai kết hợp cấu trúc và ngữ nghĩa
- Tạo đoạn đặc biệt cho định nghĩa và điều khoản quan trọng
- Áp dụng Small2Big để bảo toàn ngữ cảnh pháp lý
Kết quả:
- Cải thiện 45% độ chính xác truy xuất
- Giảm 30% tỷ lệ câu trả lời sai
8.2. Tình huống 2: Trợ lý ảo cho tài liệu kỹ thuật
Thách thức:
- Nội dung kỹ thuật cao với nhiều thuật ngữ chuyên ngành
- Cần bảo toàn mối quan hệ giữa các phần
- Xử lý hình ảnh, biểu đồ và mã nguồn
Giải pháp:
- Phân đoạn đa cấp với lưu trữ mối quan hệ phân cấp
- Xử lý đặc biệt cho mã nguồn và dữ liệu kỹ thuật
- Tích hợp OCR cho hình ảnh và biểu đồ
Kết quả:
- Tăng 60% khả năng trả lời câu hỏi kỹ thuật phức tạp
- Cải thiện trải nghiệm người dùng với thời gian phản hồi nhanh hơn
9. Kết luận và hướng phát triển tương lai
Chunk Engineering là một yếu tố quan trọng quyết định hiệu suất của hệ thống RAG. Việc lựa chọn và triển khai chiến lược phân đoạn phù hợp có thể cải thiện đáng kể chất lượng truy xuất và độ chính xác của câu trả lời.
Các xu hướng tương lai trong lĩnh vực này bao gồm:
- Phân đoạn tự động hóa: Sử dụng AI để tự động xác định chiến lược phân đoạn tối ưu
- Phân đoạn đa phương thức: Mở rộng kỹ thuật phân đoạn cho dữ liệu đa phương thức (văn bản, hình ảnh, âm thanh)
- Phân đoạn động: Điều chỉnh chiến lược phân đoạn trong thời gian thực dựa trên phản hồi và kết quả
- Tiêu chuẩn hóa: Phát triển các tiêu chuẩn và thực tiễn tốt nhất cho Chunk Engineering
Với sự phát triển không ngừng của các mô hình ngôn ngữ lớn và ứng dụng RAG, Chunk Engineering sẽ tiếp tục là một lĩnh vực nghiên cứu và phát triển quan trọng, mở ra nhiều cơ hội để cải thiện khả năng truy xuất và tổng hợp thông tin của các hệ thống AI.
Tài liệu tham khảo
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., ... & Kiela, D. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Advances in Neural Information Processing Systems, 33, 9459-9468. https://proceedings.neurips.cc/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf
- Gao, L., Ma, X., Lin, J., & Callan, J. (2024). "Searching for Best Practices in Retrieval-Augmented Generation." arXiv preprint arXiv:2407.01219. https://arxiv.org/abs/2407.01219
- Goyal, R. (2024). "Chunking Best Practices for Retrieval Augmented Generation (RAG) Applications." LinkedIn Pulse. https://linkedin.com/pulse/chunking-best-practices-retrieval-augmented-generation-rishabh-goyal-hol3c
- Ahmed, S. (2024). "Mastering Chunking Strategies for Retrieval-Augmented Generation (RAG)." Medium. https://medium.com/@sahin.samia/mastering-chunking-strategies-for-retrieval-augmented-generation-rag-c0d3d09f80f2
- Mishra, A. (2024). "Five Levels of Chunking Strategies in RAG." Medium. https://medium.com/@anuragmishra_27746/five-levels-of-chunking-strategies-in-rag-notes-from-gregs-video-7b735895694d
- Databricks. (2024). "Mastering Chunking Strategies for RAG: Best Practices & Code Examples." Databricks Community Blog. https://community.databricks.com/t5/technical-blog/the-ultimate-guide-to-chunking-strategies-for-rag-applications/ba-p/113089
- Analytics Vidhya. (2025). "15 Chunking Techniques to Build Exceptional RAGs Systems." Analytics Vidhya. https://analyticsvidhya.com/blog/2024/10/chunking-techniques-to-build-exceptional-rag-systems
- Danter, D. (2024). "Advanced Chunking and Search Methods for Improved Retrieval Augmented Generation." CMS Conference Proceedings. https://openaccess.cms-conferences.org/publications/book/978-1-964867-35-9/article/978-1-964867-35-9_194
- Procogia. (2024). "Advanced RAG Techniques: Small2Big Chunking Explained." Procogia Blog. https://procogia.com/unlocking-rags-potential-mastering-advanced-techniques-part-1
- Airbyte. (2025). "5 Chunking Strategies For RAG Applications." Airbyte Blog. https://airbyte.com/data-engineering-resources/chunk-text-for-rag