Hybrid Search trong RAG: Kỹ thuật Tối ưu hóa Truy xuất Thông tin
Hybrid Search kết hợp tìm kiếm dựa trên từ khóa và vector để tối ưu hóa quá trình truy xuất trong RAG, mang lại kết quả chính xác hơn và toàn diện hơn so với các phương pháp truyền thống.
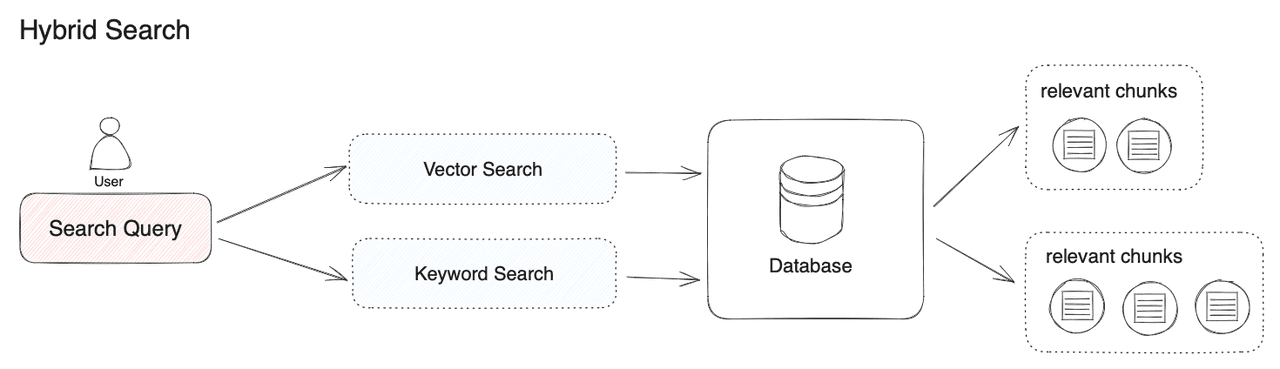
Tổng quan về Hybrid Search trong RAG
Hybrid Search là một phương pháp tìm kiếm tiên tiến trong hệ thống Retrieval Augmented Generation (RAG), kết hợp hai phương pháp tìm kiếm khác nhau: tìm kiếm dựa trên từ khóa (keyword-based search) và tìm kiếm dựa trên vector (vector-based search). Bằng cách tận dụng điểm mạnh của cả hai phương pháp, Hybrid Search cung cấp kết quả truy xuất toàn diện hơn, chính xác hơn, đặc biệt trong các trường hợp phức tạp hoặc khi dữ liệu đa dạng (Akash, 2024).
Trong bối cảnh RAG, việc tối ưu hóa thành phần truy xuất (retrieval component) là yếu tố quyết định đến chất lượng của đầu ra cuối cùng. Hybrid Search đã trở thành một giải pháp hiệu quả để giải quyết những hạn chế của các phương pháp truy xuất truyền thống, đặc biệt khi xử lý các truy vấn phức tạp hoặc đa nghĩa.
Cơ chế hoạt động của Hybrid Search
Hybrid Search hoạt động bằng cách kết hợp hai phương pháp tìm kiếm chính:
1. Tìm kiếm dựa trên từ khóa (Keyword-based Search)
Phương pháp này, thường sử dụng thuật toán BM25 (Best Matching 25), tập trung vào việc tìm kiếm các tài liệu chứa chính xác các từ khóa trong truy vấn. BM25 là một mô hình xếp hạng dựa trên xác suất, đánh giá mức độ liên quan của tài liệu dựa trên tần suất xuất hiện của từ khóa trong tài liệu và độ hiếm của từ khóa trong toàn bộ kho dữ liệu (Poudel, 2024).
Ưu điểm của tìm kiếm dựa trên từ khóa:
- Hiệu quả trong việc tìm kiếm các thuật ngữ chính xác, số liệu, tên riêng
- Không yêu cầu tính toán phức tạp
- Hoạt động tốt với các truy vấn có cấu trúc rõ ràng
Nhược điểm:
- Không hiểu được ngữ cảnh hoặc ngữ nghĩa
- Gặp khó khăn với các từ đồng nghĩa hoặc cách diễn đạt khác nhau
- Không hiệu quả với các truy vấn mơ hồ hoặc trừu tượng
2. Tìm kiếm dựa trên vector (Vector-based Search)
Phương pháp này chuyển đổi cả truy vấn và tài liệu thành các vector nhúng (embeddings) trong không gian đa chiều, sau đó tính toán độ tương đồng giữa chúng. Các thuật toán phổ biến như FAISS (Facebook AI Similarity Search) được sử dụng để tìm kiếm hiệu quả trong không gian vector (Superlinked, 2024).
Ưu điểm của tìm kiếm dựa trên vector:
- Hiểu được ngữ nghĩa và ngữ cảnh của nội dung
- Xử lý tốt các truy vấn mơ hồ hoặc trừu tượng
- Nhận diện được các mối quan hệ ngữ nghĩa giữa các khái niệm
Nhược điểm:
- Có thể bỏ qua các thuật ngữ chính xác hoặc chi tiết cụ thể
- Yêu cầu tính toán phức tạp hơn
- Phụ thuộc vào chất lượng của mô hình nhúng
Hybrid Search kết hợp cả hai phương pháp này để tận dụng điểm mạnh và bù đắp điểm yếu của mỗi phương pháp, tạo ra một hệ thống truy xuất toàn diện hơn (Weaviate, 2025).
Các phương pháp kết hợp kết quả trong Hybrid Search
Một trong những thách thức lớn nhất của Hybrid Search là cách kết hợp kết quả từ hai phương pháp tìm kiếm khác nhau. Dưới đây là các phương pháp phổ biến:
1. Reciprocal Rank Fusion (RRF)
RRF là một trong những phương pháp phổ biến nhất để kết hợp kết quả từ nhiều nguồn tìm kiếm. Phương pháp này tính điểm cho mỗi tài liệu dựa trên thứ hạng của nó trong mỗi danh sách kết quả, sau đó kết hợp chúng lại (Microsoft, 2024).
Công thức RRF cơ bản:
RRF_score(d) = Σ 1/(k + r(d))
Trong đó:
- d là tài liệu
- r(d) là thứ hạng của tài liệu d trong danh sách kết quả
- k là hằng số (thường là 60) để giảm ảnh hưởng của các tài liệu xếp hạng cao
RRF hiệu quả vì nó không yêu cầu chuẩn hóa điểm số giữa các hệ thống khác nhau và có thể xử lý các danh sách kết quả có độ dài khác nhau.
2. Linear Combination
Phương pháp này kết hợp điểm số từ cả hai phương pháp tìm kiếm bằng cách sử dụng trọng số:
Final_score = α * BM25_score + (1-α) * Vector_score
Trong đó α là tham số điều chỉnh mức độ ảnh hưởng của mỗi phương pháp. Việc chọn giá trị α phù hợp thường đòi hỏi thử nghiệm và tối ưu hóa (Muñoz, 2024).
3. Reranking
Reranking là một kỹ thuật nâng cao, trong đó kết quả ban đầu từ một hoặc cả hai phương pháp tìm kiếm được xếp hạng lại bằng một mô hình học máy chuyên biệt. Mô hình này được huấn luyện để đánh giá mức độ liên quan giữa truy vấn và tài liệu một cách chính xác hơn (Superlinked, 2024).
Quy trình Reranking thường bao gồm:
- Thu thập kết quả ban đầu từ các phương pháp tìm kiếm
- Sử dụng mô hình reranker để đánh giá lại mức độ liên quan của mỗi tài liệu
- Sắp xếp lại kết quả dựa trên điểm số mới
Các mô hình reranker phổ biến bao gồm Cross-Encoder, được huấn luyện đặc biệt để đánh giá sự liên quan giữa cặp truy vấn-tài liệu.
4. Ensemble Methods
Phương pháp tổng hợp (Ensemble) sử dụng nhiều chiến lược kết hợp khác nhau và chọn kết quả tốt nhất dựa trên bối cảnh cụ thể. Trong LangChain, EnsembleRetriever là một công cụ phổ biến cho phép kết hợp nhiều bộ truy xuất khác nhau (Muñoz, 2024).
Triển khai Hybrid Search trong RAG
Việc triển khai Hybrid Search trong hệ thống RAG thường bao gồm các bước sau:
1. Chuẩn bị dữ liệu
- Tiền xử lý văn bản: Làm sạch, chuẩn hóa và phân đoạn tài liệu thành các đơn vị nhỏ hơn (chunks)
- Tạo chỉ mục từ khóa: Xây dựng chỉ mục ngược (inverted index) cho tìm kiếm BM25
- Tạo vector nhúng: Chuyển đổi tài liệu thành vector nhúng sử dụng mô hình như OpenAI's text-embedding-ada-002 hoặc các mô hình mã nguồn mở như BERT, Sentence Transformers
2. Xây dựng pipeline truy xuất
# Ví dụ triển khai đơn giản với LangChain
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
# Tạo bộ truy xuất dựa trên từ khóa
bm25_retriever = BM25Retriever.from_documents(documents)
# Tạo bộ truy xuất dựa trên vector
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
vector_retriever = vectorstore.as_retriever()
# Kết hợp hai bộ truy xuất với trọng số
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5]
)
# Truy xuất tài liệu
retrieved_docs = ensemble_retriever.get_relevant_documents("truy vấn của người dùng")
3. Tích hợp với mô hình ngôn ngữ lớn (LLM)
Sau khi truy xuất tài liệu liên quan, chúng được đưa vào ngữ cảnh cho LLM để tạo ra câu trả lời:
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# Tạo chuỗi RAG
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="stuff",
retriever=ensemble_retriever
)
# Trả lời câu hỏi
response = qa_chain.run("câu hỏi của người dùng")
4. Tối ưu hóa và đánh giá
Để tối ưu hóa hiệu suất của Hybrid Search, cần thực hiện:
- Điều chỉnh trọng số giữa các phương pháp tìm kiếm
- Thử nghiệm với các kỹ thuật kết hợp kết quả khác nhau
- Đánh giá hiệu suất sử dụng các chỉ số như Precision, Recall, F1-score
- Phân tích lỗi để xác định các trường hợp cần cải thiện
So sánh hiệu suất với các phương pháp truy xuất khác
Nhiều nghiên cứu đã chứng minh rằng Hybrid Search vượt trội so với việc chỉ sử dụng một phương pháp tìm kiếm duy nhất. Dưới đây là so sánh hiệu suất dựa trên các tình huống khác nhau:
1. Truy vấn chứa thuật ngữ chính xác
- Tìm kiếm từ khóa (BM25): Hiệu suất cao, đặc biệt khi truy vấn chứa các thuật ngữ chính xác hoặc hiếm
- Tìm kiếm vector: Có thể bỏ qua các thuật ngữ chính xác nếu chúng không phổ biến trong tập dữ liệu huấn luyện
- Hybrid Search: Kết hợp ưu điểm của cả hai, đảm bảo không bỏ sót các thuật ngữ chính xác
2. Truy vấn ngữ nghĩa hoặc trừu tượng
- Tìm kiếm từ khóa: Hiệu suất kém khi truy vấn không chứa từ khóa chính xác
- Tìm kiếm vector: Hiệu suất tốt, có thể hiểu được ngữ nghĩa và ngữ cảnh
- Hybrid Search: Duy trì hiệu suất cao của tìm kiếm vector, đồng thời bổ sung kết quả từ tìm kiếm từ khóa
3. Truy vấn đa dạng hoặc phức tạp
- Tìm kiếm từ khóa: Thường bỏ qua các khía cạnh ngữ nghĩa phức tạp
- Tìm kiếm vector: Có thể bỏ qua các chi tiết cụ thể
- Hybrid Search: Cung cấp kết quả toàn diện nhất, bao gồm cả khía cạnh ngữ nghĩa và chi tiết cụ thể
Theo một nghiên cứu được thực hiện bởi Superlinked (2024), Hybrid Search kết hợp với Reranking có thể cải thiện độ chính xác truy xuất lên đến 25% so với chỉ sử dụng tìm kiếm vector và 40% so với chỉ sử dụng tìm kiếm từ khóa.
Các thách thức và giải pháp khi triển khai Hybrid Search
1. Cân bằng trọng số
Thách thức: Xác định trọng số tối ưu giữa tìm kiếm từ khóa và tìm kiếm vector là một thách thức lớn, đặc biệt khi các truy vấn có tính chất khác nhau.
Giải pháp:
- Sử dụng học máy để tự động điều chỉnh trọng số dựa trên loại truy vấn
- Thực hiện thử nghiệm A/B để xác định trọng số tối ưu cho từng loại truy vấn
- Triển khai hệ thống phân loại truy vấn để áp dụng trọng số khác nhau cho từng loại
2. Hiệu suất tính toán
Thách thức: Hybrid Search đòi hỏi tính toán cho cả hai phương pháp tìm kiếm, có thể dẫn đến độ trễ cao hơn.
Giải pháp:
- Sử dụng kỹ thuật song song hóa để thực hiện đồng thời cả hai phương pháp tìm kiếm
- Áp dụng caching cho các truy vấn phổ biến
- Sử dụng các thuật toán tối ưu như Approximate Nearest Neighbors (ANN) cho tìm kiếm vector
- Triển khai hệ thống phân tầng, chỉ áp dụng Hybrid Search cho các truy vấn phức tạp
3. Chất lượng vector nhúng
Thách thức: Hiệu suất của tìm kiếm vector phụ thuộc rất nhiều vào chất lượng của mô hình nhúng.
Giải pháp:
- Sử dụng các mô hình nhúng tiên tiến như OpenAI's text-embedding-3-small hoặc các mô hình mã nguồn mở chất lượng cao
- Fine-tune mô hình nhúng cho miền dữ liệu cụ thể
- Thử nghiệm với nhiều mô hình nhúng khác nhau để tìm ra mô hình phù hợp nhất
4. Xử lý dữ liệu đa dạng
Thách thức: Dữ liệu thực tế thường đa dạng và không đồng nhất, gây khó khăn cho việc áp dụng một chiến lược tìm kiếm duy nhất.
Giải pháp:
- Phân loại dữ liệu và áp dụng các chiến lược tìm kiếm khác nhau cho từng loại
- Sử dụng các kỹ thuật tiền xử lý đặc biệt cho từng loại dữ liệu
- Triển khai các bộ truy xuất chuyên biệt cho từng loại dữ liệu và kết hợp kết quả
Tương lai của Hybrid Search trong RAG
Hybrid Search đang không ngừng phát triển với nhiều hướng nghiên cứu và cải tiến mới:
1. Hybrid Search đa mô thức (Multimodal Hybrid Search)
Mở rộng Hybrid Search để xử lý dữ liệu đa mô thức như văn bản, hình ảnh, âm thanh và video. Điều này đòi hỏi việc phát triển các kỹ thuật nhúng đa mô thức và các phương pháp kết hợp kết quả phức tạp hơn.
2. Hybrid Search thích ứng (Adaptive Hybrid Search)
Phát triển các hệ thống có khả năng tự động điều chỉnh chiến lược tìm kiếm dựa trên loại truy vấn, ngữ cảnh người dùng và phản hồi. Các kỹ thuật học tăng cường (reinforcement learning) có thể được áp dụng để tối ưu hóa liên tục chiến lược tìm kiếm.
3. Hybrid Search phân tán (Distributed Hybrid Search)
Triển khai Hybrid Search trên các hệ thống phân tán để xử lý khối lượng dữ liệu lớn và đảm bảo khả năng mở rộng. Điều này đòi hỏi các kỹ thuật tối ưu hóa cho việc phân phối chỉ mục và kết hợp kết quả từ nhiều nút.
4. Hybrid Search với mô hình ngôn ngữ lớn
Tích hợp chặt chẽ hơn giữa Hybrid Search và các mô hình ngôn ngữ lớn, cho phép LLM tham gia vào quá trình truy xuất thông qua các kỹ thuật như query reformulation, iterative retrieval, và hypothetical document embeddings.
Tài liệu tham khảo
- Akash, C. S. (2024). Hybrid Search a method to Optimize RAG implementation. Medium. https://medium.com/@csakash03/hybrid-search-is-a-method-to-optimize-rag-implementation-98d9d0911341
- Microsoft. (2024). Optimizing Retrieval for RAG Apps: Vector Search and Hybrid Techniques. Microsoft Tech Community. https://techcommunity.microsoft.com/blog/educatordeveloperblog/optimizing-retrieval-for-rag-apps-vector-search-and-hybrid-techniques/4138030
- Muñoz, E. (2024). Rerank-Fusion-Ensemble-Hybrid-Search. GitHub. https://github.com/edumunozsala/langchain-rag-techniques/blob/main/Rerank-Fusion-Ensemble-Hybrid-Search.ipynb
- Poudel, N. (2024). Advanced RAG Implementation using Hybrid Search and Reranking with Zephyr Alpha LLM. Medium. https://medium.com/@nadikapoudel16/advanced-rag-implementation-using-hybrid-search-reranking-with-zephyr-alpha-llm-4340b55fef22
- Superlinked. (2024). Optimizing RAG with Hybrid Search & Reranking. Superlinked VectorHub. https://superlinked.com/vectorhub/articles/optimizing-rag-with-hybrid-search-reranking
- Weaviate. (2025). Hybrid Search Explained. Weaviate Blog. https://weaviate.io/blog/hybrid-search-explained
- Oracle. (2024). Implement Simple Hybrid Search for Retrieval Augmented Generation. Oracle Documentation. https://docs.oracle.com/en/learn/oracledb-hybrid-search/index.html
- DataStax. (2025). How to Implement Hybrid Search in RAG Pipelines for LLMs. DataStax Guides. https://datastax.com/guides/hybrid-search-rag-pipelines
- Athina AI. (2024). Advanced RAG Implementation using Hybrid Search. Athina AI Hub. https://hub.athina.ai/athina-originals/advanced-rag-implementation-using-hybrid-search
- Elastic. (2024). A Comprehensive Hybrid Search Guide. Elastic. https://elastic.co/what-is/hybrid-search