Hierarchical Indexing trong RAG: Phương pháp Nâng cao Hiệu suất Truy xuất Thông tin
Khám phá cách Hierarchical Indexing cách mạng hóa hệ thống RAG với cấu trúc phân cấp thông minh, giúp truy xuất thông tin chính xác và nhanh hơn so với phương pháp truyền thống.

1. Tổng quan về Hierarchical Indexing
Hierarchical Indexing (Lập chỉ mục phân cấp) là một phương pháp tiên tiến trong hệ thống Retrieval-Augmented Generation (RAG), nhằm tối ưu hóa quá trình truy xuất thông tin bằng cách tổ chức dữ liệu theo cấu trúc phân cấp. Thay vì sử dụng một chỉ mục phẳng truyền thống, phương pháp này tạo ra nhiều lớp chỉ mục, cho phép hệ thống truy vấn thông tin theo cách tiếp cận từ tổng quát đến chi tiết.
Hierarchical Indexing giải quyết một số thách thức quan trọng trong hệ thống RAG truyền thống:
- Cải thiện hiệu suất truy xuất khi làm việc với tập dữ liệu lớn
- Tăng độ chính xác của thông tin được truy xuất
- Giảm thiểu vấn đề "nhiễu thông tin" khi truy vấn
- Tối ưu hóa việc sử dụng tài nguyên tính toán
2. Cấu trúc của Hierarchical Indexing
Một hệ thống Hierarchical Indexing điển hình trong RAG thường bao gồm các lớp chỉ mục sau:
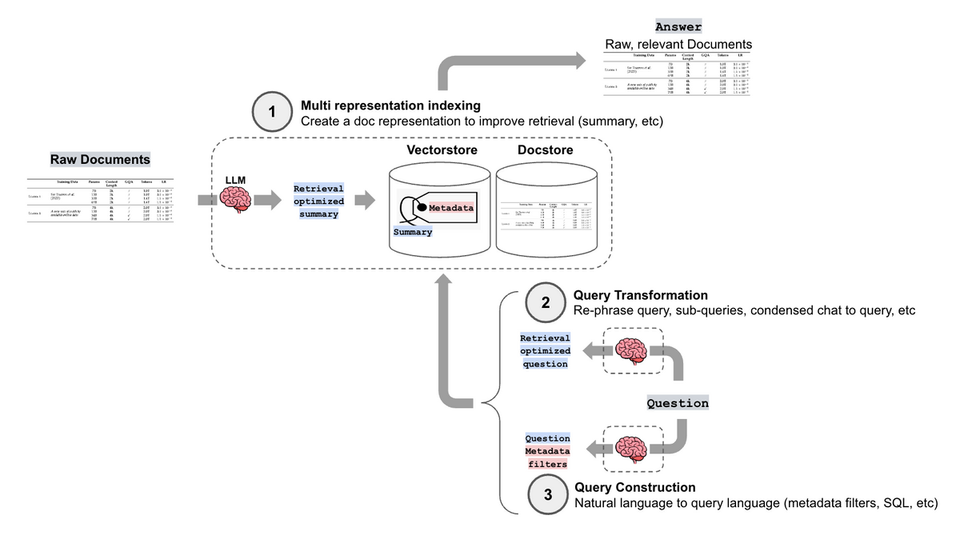
2.1. Lớp tổng quan (Summary Layer)
Lớp này chứa các vector nhúng (embeddings) đại diện cho thông tin tổng quan của tài liệu hoặc các phần lớn của tài liệu. Mỗi vector trong lớp này thường đại diện cho:
- Tóm tắt của toàn bộ tài liệu
- Tiêu đề chính và các tiêu đề phụ
- Thông tin meta của tài liệu
Lớp tổng quan giúp hệ thống nhanh chóng xác định các tài liệu hoặc phần tài liệu có liên quan nhất đến truy vấn của người dùng.
2.2. Lớp trung gian (Intermediate Layer)
Tùy thuộc vào độ phức tạp của dữ liệu, hệ thống có thể có một hoặc nhiều lớp trung gian. Các lớp này chứa thông tin chi tiết hơn so với lớp tổng quan nhưng vẫn chưa đi vào chi tiết cụ thể. Ví dụ:
- Các đoạn văn hoặc phần nhỏ hơn của tài liệu
- Các chủ đề con trong mỗi phần lớn
- Các mối quan hệ giữa các phần khác nhau của tài liệu
2.3. Lớp chi tiết (Detail Layer)
Đây là lớp chứa thông tin chi tiết nhất, thường là các đoạn văn nhỏ, câu hoặc thậm chí là các thực thể cụ thể. Lớp này được truy cập sau khi hệ thống đã xác định được phần tài liệu có liên quan thông qua các lớp trên.
3. Cách thức hoạt động của Hierarchical Indexing
Quá trình truy xuất thông tin trong Hierarchical Indexing diễn ra theo các bước sau:
3.1. Xây dựng chỉ mục phân cấp
- Phân đoạn tài liệu: Tài liệu được chia thành các phần với nhiều cấp độ chi tiết khác nhau.
- Tạo tóm tắt: Sử dụng mô hình ngôn ngữ để tạo tóm tắt cho mỗi phần của tài liệu.
- Tạo vector nhúng: Chuyển đổi các phần tài liệu và tóm tắt thành vector nhúng sử dụng mô hình embedding.
- Tổ chức phân cấp: Xây dựng cấu trúc phân cấp liên kết các vector nhúng ở các cấp độ khác nhau.
3.2. Quá trình truy xuất
- Truy vấn lớp tổng quan: Hệ thống bắt đầu bằng việc so sánh truy vấn của người dùng với các vector trong lớp tổng quan để xác định các tài liệu hoặc phần tài liệu có liên quan nhất.
- Truy vấn lớp trung gian: Sau khi xác định được các tài liệu có liên quan, hệ thống tiếp tục tìm kiếm trong lớp trung gian của các tài liệu đó.
- Truy vấn lớp chi tiết: Cuối cùng, hệ thống truy xuất thông tin chi tiết từ các phần cụ thể đã được xác định.
- Tổng hợp kết quả: Thông tin từ các lớp khác nhau được tổng hợp để tạo ra câu trả lời cuối cùng.
Quá trình này giúp hệ thống tập trung vào những phần có liên quan nhất của dữ liệu, thay vì phải tìm kiếm trong toàn bộ cơ sở dữ liệu.
4. Các kỹ thuật triển khai Hierarchical Indexing
4.1. Parent-Child Indexing
Đây là phương pháp phổ biến nhất, trong đó mỗi nút con (child node) được liên kết với một nút cha (parent node). Quá trình truy xuất bắt đầu từ nút cha và sau đó đi xuống các nút con có liên quan.
# Ví dụ đơn giản về Parent-Child Indexing
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# Bước 1: Phân đoạn tài liệu thành các phần lớn (parent chunks)
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
parent_chunks = parent_splitter.split_text(document_text)
# Bước 2: Tạo tóm tắt cho mỗi phần lớn
parent_summaries = []
for chunk in parent_chunks:
summary = summarize_text(chunk) # Hàm tóm tắt sử dụng LLM
parent_summaries.append(summary)
# Bước 3: Tạo chỉ mục vector cho các tóm tắt
parent_vectorstore = Chroma.from_texts(
texts=parent_summaries,
embedding=OpenAIEmbeddings(),
collection_name="parent_index"
)
# Bước 4: Phân đoạn mỗi phần lớn thành các phần nhỏ hơn (child chunks)
child_chunks = []
child_to_parent_mapping = {} # Lưu trữ mối quan hệ giữa child và parent
for i, parent_chunk in enumerate(parent_chunks):
child_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
children = child_splitter.split_text(parent_chunk)
for child in children:
child_chunks.append(child)
child_to_parent_mapping[child] = i # Lưu chỉ số của parent
# Bước 5: Tạo chỉ mục vector cho các phần nhỏ
child_vectorstore = Chroma.from_texts(
texts=child_chunks,
embedding=OpenAIEmbeddings(),
collection_name="child_index"
)
4.2. Tree-based Indexing
Phương pháp này tổ chức dữ liệu theo cấu trúc cây, cho phép truy xuất thông tin theo nhiều nhánh khác nhau. Các thuật toán như KD-Tree hoặc Ball Tree thường được sử dụng để xây dựng cấu trúc cây.
# Ví dụ về Tree-based Indexing sử dụng FAISS
import faiss
import numpy as np
from langchain.embeddings import OpenAIEmbeddings
# Tạo embeddings cho tất cả các đoạn văn
embeddings_model = OpenAIEmbeddings()
all_embeddings = [embeddings_model.embed_query(chunk) for chunk in all_chunks]
all_embeddings_array = np.array(all_embeddings).astype('float32')
# Xây dựng chỉ mục cây sử dụng FAISS
dimension = len(all_embeddings[0])
index = faiss.IndexHNSWFlat(dimension, 32) # HNSW là một thuật toán dựa trên cây
index.add(all_embeddings_array)
# Lưu chỉ mục
faiss.write_index(index, "hierarchical_tree_index.faiss")
4.3. Graph-based Indexing
Phương pháp này sử dụng cấu trúc đồ thị để biểu diễn mối quan hệ giữa các phần của tài liệu. Mỗi nút trong đồ thị đại diện cho một phần của tài liệu, và các cạnh biểu thị mối quan hệ giữa chúng.
# Ví dụ đơn giản về Graph-based Indexing
import networkx as nx
from langchain.embeddings import OpenAIEmbeddings
# Tạo đồ thị
document_graph = nx.DiGraph()
# Thêm các nút (nodes) vào đồ thị
for i, chunk in enumerate(all_chunks):
document_graph.add_node(i, text=chunk)
# Thêm các cạnh (edges) dựa trên mối quan hệ ngữ nghĩa
embeddings_model = OpenAIEmbeddings()
for i in range(len(all_chunks)):
for j in range(i+1, len(all_chunks)):
# Tính độ tương đồng giữa hai đoạn văn
embedding_i = embeddings_model.embed_query(all_chunks[i])
embedding_j = embeddings_model.embed_query(all_chunks[j])
similarity = cosine_similarity(embedding_i, embedding_j)
# Nếu độ tương đồng vượt ngưỡng, thêm cạnh vào đồ thị
if similarity > 0.7:
document_graph.add_edge(i, j, weight=similarity)
document_graph.add_edge(j, i, weight=similarity)
# Lưu đồ thị
nx.write_gpickle(document_graph, "document_graph.gpickle")
5. Ứng dụng Hierarchical Indexing trong các hệ thống RAG
5.1. Truy xuất tài liệu dài
Hierarchical Indexing đặc biệt hiệu quả khi làm việc với tài liệu dài như sách, báo cáo kỹ thuật, hoặc tài liệu pháp lý. Hệ thống có thể nhanh chóng xác định các chương hoặc phần có liên quan trước khi đi vào chi tiết.
5.2. Hệ thống hỏi đáp phức tạp
Đối với các câu hỏi phức tạp đòi hỏi thông tin từ nhiều nguồn khác nhau, Hierarchical Indexing giúp hệ thống tìm kiếm thông tin một cách có hệ thống và toàn diện.
5.3. Tóm tắt tài liệu đa cấp
Hệ thống có thể tạo ra các bản tóm tắt ở nhiều cấp độ chi tiết khác nhau, từ tổng quan đến chi tiết, giúp người dùng nhanh chóng nắm bắt thông tin quan trọng.
5.4. Phân tích ý kiến và đánh giá
Trong các ứng dụng phân tích ý kiến, Hierarchical Indexing giúp tổ chức và truy xuất thông tin theo chủ đề, mức độ tình cảm, hoặc các khía cạnh khác của ý kiến.
6. So sánh với các phương pháp indexing khác trong RAG
6.1. Flat Indexing (Chỉ mục phẳng)
Ưu điểm của Hierarchical Indexing so với Flat Indexing:
- Hiệu quả hơn khi làm việc với tập dữ liệu lớn
- Giảm thời gian truy vấn bằng cách thu hẹp không gian tìm kiếm
- Cải thiện độ chính xác của kết quả truy xuất
- Tiết kiệm tài nguyên tính toán
Nhược điểm:
- Phức tạp hơn trong việc triển khai
- Yêu cầu nhiều bước xử lý hơn trong quá trình xây dựng chỉ mục
6.2. Dense Passage Retrieval (DPR)
Ưu điểm của Hierarchical Indexing so với DPR:
- Khả năng xử lý các mối quan hệ phức tạp giữa các phần của tài liệu
- Hiệu quả hơn khi truy xuất thông tin từ tài liệu dài
- Giảm thiểu vấn đề "mất ngữ cảnh" khi truy xuất các đoạn văn riêng lẻ
Nhược điểm:
- Yêu cầu nhiều tài nguyên hơn để xây dựng và duy trì chỉ mục
- Có thể chậm hơn đối với các truy vấn đơn giản
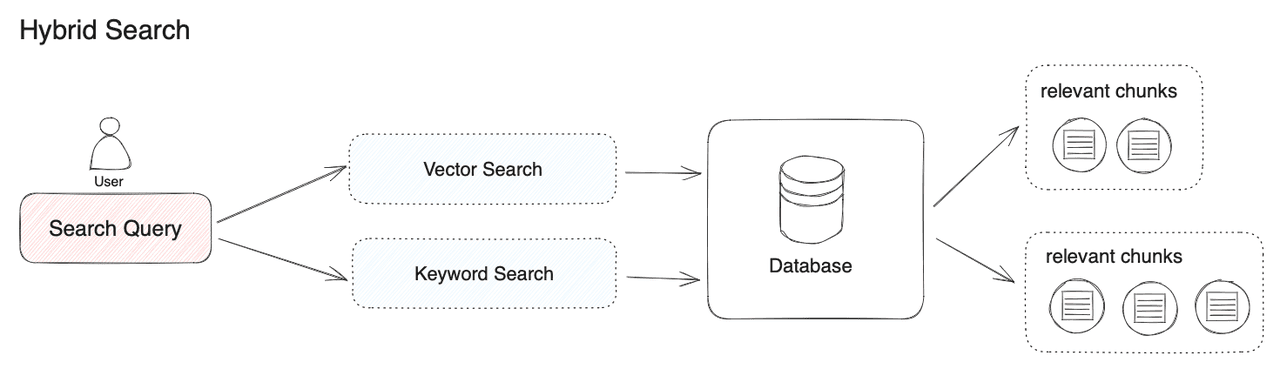
6.3. Hybrid Search
Ưu điểm của Hierarchical Indexing khi kết hợp với Hybrid Search:
- Cải thiện cả độ chính xác và hiệu suất của truy vấn
- Kết hợp được ưu điểm của tìm kiếm ngữ nghĩa và tìm kiếm từ khóa
- Linh hoạt hơn trong việc xử lý các loại truy vấn khác nhau
7. Thách thức và giải pháp khi triển khai Hierarchical Indexing
7.1. Thách thức về hiệu suất
Thách thức:
- Quá trình xây dựng chỉ mục phân cấp có thể tốn nhiều thời gian và tài nguyên
- Cập nhật chỉ mục phức tạp hơn so với chỉ mục phẳng
Giải pháp:
- Sử dụng kỹ thuật xây dựng chỉ mục theo batch hoặc incremental indexing
- Tối ưu hóa quá trình tạo vector nhúng bằng cách sử dụng mô hình nhẹ hơn cho các lớp cao hơn
- Áp dụng kỹ thuật song song hóa trong quá trình xây dựng chỉ mục
7.2. Thách thức về độ chính xác
Thách thức:
- Việc tóm tắt có thể làm mất thông tin quan trọng
- Lỗi ở các lớp cao có thể lan truyền xuống các lớp thấp hơn
Giải pháp:
- Sử dụng mô hình ngôn ngữ mạnh mẽ để tạo tóm tắt chất lượng cao
- Áp dụng kỹ thuật truy xuất đa đường dẫn (multi-path retrieval)
- Kết hợp với các phương pháp tìm kiếm khác để đảm bảo không bỏ sót thông tin quan trọng
7.3. Thách thức về thiết kế cấu trúc phân cấp
Thách thức:
- Xác định số lượng lớp tối ưu cho mỗi ứng dụng cụ thể
- Thiết kế cấu trúc phân cấp phù hợp với đặc điểm của dữ liệu
Giải pháp:
- Thực hiện thử nghiệm với các cấu trúc phân cấp khác nhau
- Sử dụng kỹ thuật học máy để tự động xác định cấu trúc phân cấp tối ưu
- Áp dụng phương pháp thiết kế thích ứng dựa trên đặc điểm của dữ liệu
8. Xu hướng phát triển và nghiên cứu mới
8.1. Hierarchical RAG (HRAG)
HRAG là một phiên bản nâng cao của RAG, tận dụng cấu trúc phân cấp không chỉ trong quá trình lập chỉ mục mà còn trong quá trình tạo ra câu trả lời. Hệ thống này có khả năng tạo ra các câu trả lời ở nhiều cấp độ chi tiết khác nhau, từ tổng quan đến chi tiết.
8.2. GraphRAG
GraphRAG kết hợp Hierarchical Indexing với cấu trúc đồ thị tri thức để nâng cao khả năng suy luận và hiểu ngữ cảnh. Phương pháp này đặc biệt hiệu quả khi làm việc với dữ liệu có mối quan hệ phức tạp.
8.3. Adaptive Hierarchical Indexing
Đây là phương pháp lập chỉ mục phân cấp thích ứng, trong đó cấu trúc phân cấp được điều chỉnh tự động dựa trên đặc điểm của dữ liệu và mẫu truy vấn. Hệ thống có thể thay đổi số lượng lớp, kích thước của mỗi phần, và các tham số khác để tối ưu hóa hiệu suất.
8.4. Multi-modal Hierarchical Indexing
Phương pháp này mở rộng Hierarchical Indexing để làm việc với dữ liệu đa phương thức, bao gồm văn bản, hình ảnh, âm thanh, và video. Mỗi phương thức có thể có cấu trúc phân cấp riêng, và các cấu trúc này được liên kết với nhau để tạo thành một hệ thống truy xuất thông tin toàn diện.
9. Kết luận
Hierarchical Indexing là một phương pháp mạnh mẽ để nâng cao hiệu suất của hệ thống RAG, đặc biệt khi làm việc với tập dữ liệu lớn và phức tạp. Bằng cách tổ chức thông tin theo cấu trúc phân cấp, phương pháp này giúp hệ thống truy xuất thông tin một cách hiệu quả và chính xác hơn.
Mặc dù việc triển khai Hierarchical Indexing đòi hỏi nhiều nỗ lực hơn so với các phương pháp lập chỉ mục truyền thống, nhưng lợi ích mà nó mang lại - bao gồm cải thiện độ chính xác, giảm thời gian truy vấn, và khả năng xử lý dữ liệu phức tạp - làm cho nó trở thành một công cụ không thể thiếu trong bộ công cụ của các nhà phát triển hệ thống RAG hiện đại.
Với sự phát triển liên tục của các kỹ thuật mới như HRAG, GraphRAG, và Multi-modal Hierarchical Indexing, chúng ta có thể kỳ vọng vào những cải tiến đáng kể trong hiệu suất và khả năng của hệ thống RAG trong tương lai.
Tài liệu tham khảo
- Hosking, T. (2024). Hierarchical Indexing for Retrieval-Augmented Opinion Summarization. Transactions of the Association for Computational Linguistics. https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00703/125483/Hierarchical-Indexing-for-Retrieval-Augmented
- Diamant, N. (2024). Hierarchical Indices: Enhancing RAG Systems. Medium. https://medium.com/@nirdiamant21/hierarchical-indices-enhancing-rag-systems-43c06330c085
- PIXION Blog. (2024). RAG Strategies - Hierarchical Index Retrieval. https://pixion.co/blog/rag-strategies-hierarchical-index-retrieval
- Sahaj.ai. (2024). Exploring Hierarchical RAG: An Advanced Technique for Robust Information Retrieval. https://sahaj.ai/exploring-hierarchical-rag-an-advanced-technique-for-robust-information-retrieval
- LanceDB. (2024). GraphRAG: Hierarchical approach to Retrieval Augmented Generation. https://blog.lancedb.com/graphrag-hierarchical-approach-to-retrieval-augmented-generation
- Clarifai. (2023). What is RAG? (Retrieval Augmented Generation). https://clarifai.com/blog/what-is-rag-retrieval-augmented-generation
- Machine Learning Mastery. (2024). Understanding RAG Part VII: Vector Databases & Indexing Strategies. https://machinelearningmastery.com/understanding-rag-part-vii-vector-databases-indexing-strategies
- MyScale. (2024). Understanding Vector Indexing: A Comprehensive Guide. https://myscale.com/blog/everything-about-vector-indexing
- NirDiamant. (2024). RAG_Techniques GitHub Repository. https://github.com/NirDiamant/RAG_Techniques/blob/main/all_rag_techniques/hierarchical_indices.ipynb