Cloudflare ra mắt thị trường tính năng cho phép website tính phí AI bot khi thu thập dữ liệu
Cloudflare vừa công bố tính năng "pay per crawl" cho phép chủ sở hữu website tính phí các AI bot khi thu thập nội dung, mở ra kỷ nguyên mới trong kiếm tiền từ dữ liệu web.

Mục lục
- Tổng quan về tính năng pay per crawl của Cloudflare
- Cách thức hoạt động của hệ thống tính phí AI bot
- Lợi ích cho chủ sở hữu website và nhà xuất bản
- Tác động đến ngành công nghiệp trí tuệ nhân tạo
- Hướng dẫn thiết lập và sử dụng tính năng
- Thách thức và cơ hội trong tương lai
Tổng quan về tính năng pay per crawl của Cloudflare
Cloudflare vừa ra mắt tính năng "pay per crawl" trong giai đoạn beta riêng tư, cho phép các chủ sở hữu nội dung tính phí AI crawler khi truy cập vào website của họ. Đây là một bước tiến quan trọng trong việc giải quyết vấn đề tranh cãi về việc các công ty trí tuệ nhân tạo thu thập dữ liệu từ web mà không có sự đồng ý hoặc bồi thường thỏa đáng.
Tính năng mới này ra đời sau khi Cloudflare đã có nhiều cuộc trò chuyện với các tổ chức báo chí, nhà xuất bản và các nền tảng truyền thông xã hội quy mô lớn. Từ những cuộc trò chuyện này, họ nhận ra một mong muốn chung: các nhà sáng tạo muốn cho phép AI crawler truy cập nội dung của họ, nhưng họ muốn được bồi thường.
Trước đây, các chủ sở hữu website chỉ có hai lựa chọn đơn giản: hoặc là để mở cửa hoàn toàn cho AI thu thập tất cả nội dung họ tạo ra, hoặc là tạo ra một "khu vườn có tường rào" bằng cách chặn hoàn toàn. Cloudflare đã tạo ra con đường thứ ba này để giải quyết tình thế khó xử mà nhiều nhà sáng tạo nội dung đang đối mặt.
Điều đặc biệt ở đây là Cloudflare đã quyết định sử dụng lại một phần gần như bị lãng quên của web: mã phản hồi HTTP 402 (Payment Required). Mã phản hồi này từ lâu đã tồn tại trong các tiêu chuẩn web nhưng hiếm khi được sử dụng trong thực tế, và giờ đây nó trở thành nền tảng cho hệ thống thanh toán mới này.
Hệ thống pay per crawl tích hợp với cơ sở hạ tầng web hiện có, tận dụng các mã trạng thái HTTP và các cơ chế xác thực đã được thiết lập để tạo ra một khung làm việc cho việc truy cập nội dung có trả phí. Cloudflare đóng vai trò là Merchant of Record (người ghi nhận giao dịch) cho tính năng pay per crawl và cũng cung cấp cơ sở hạ tầng kỹ thuật cơ bản.
Cách thức hoạt động của hệ thống tính phí AI bot
Hệ thống pay per crawl của Cloudflare hoạt động theo một cơ chế khá tinh vi, cung cấp cho chủ sở hữu tên miền quyền kiểm soát hoàn toàn chiến lược kiếm tiền của họ. Mỗi khi một AI crawler yêu cầu nội dung, họ có thể trình bày ý định thanh toán thông qua các header yêu cầu để truy cập thành công (nhận mã phản hồi HTTP 200), hoặc nhận được phản hồi 402 Payment Required kèm theo thông tin về giá cả.
Chủ sở hữu website có thể định nghĩa một mức giá cố định cho mỗi yêu cầu trên toàn bộ trang web của họ. Sau đó, các nhà xuất bản sẽ có ba lựa chọn riêng biệt đối với một crawler: Cho phép (Allow) - cấp cho crawler quyền truy cập miễn phí vào nội dung, Tính phí (Charge) - yêu cầu thanh toán với mức giá đã được cấu hình cho toàn miền, hoặc Chặn (Block) - từ chối truy cập hoàn toàn, không có tùy chọn thanh toán.
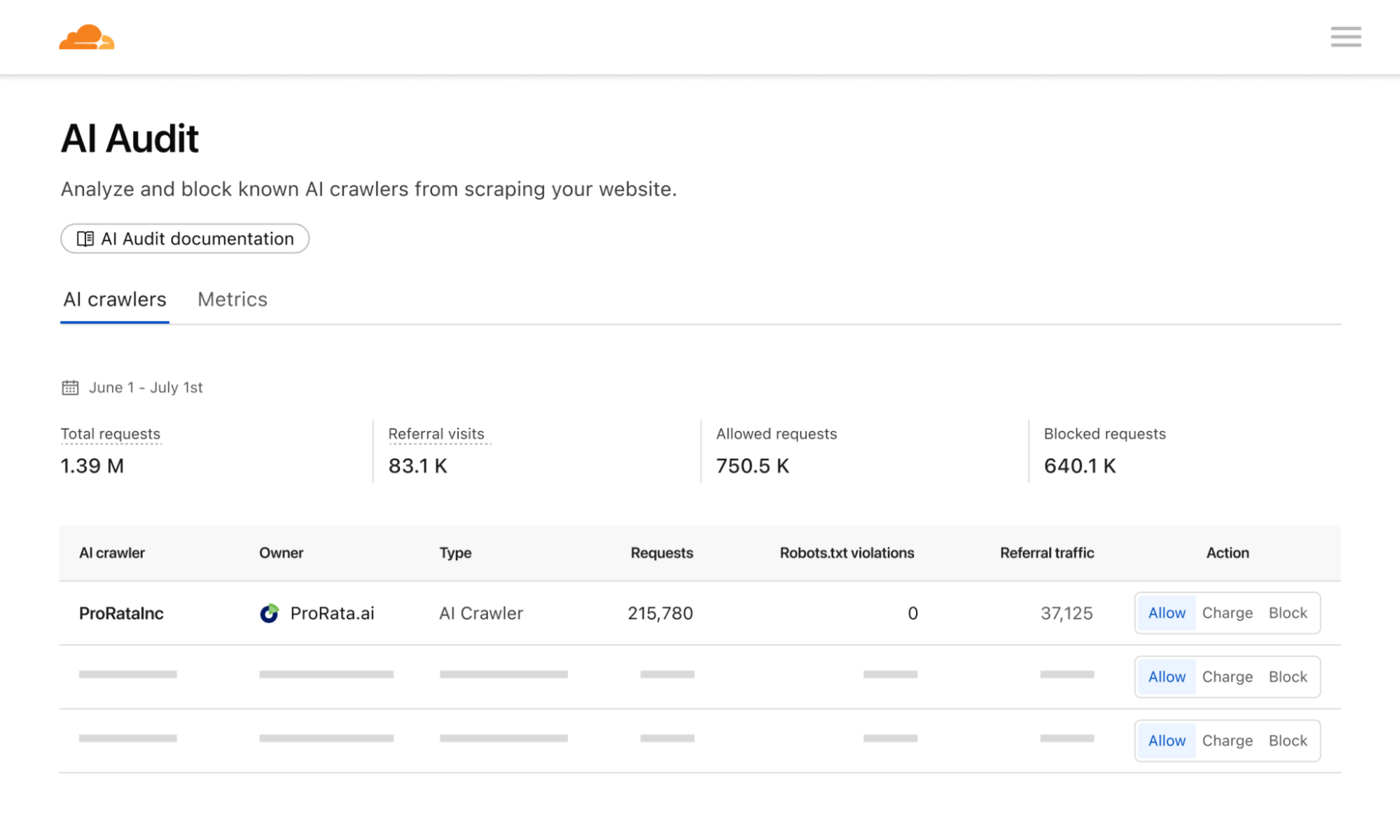
Một cơ chế quan trọng trong hệ thống này là ngay cả khi một crawler không có mối quan hệ thanh toán với Cloudflare và do đó không thể bị tính phí để truy cập, nhà xuất bản vẫn có thể chọn 'tính phí' họ. Điều này có chức năng tương đương với việc chặn ở cấp độ mạng (phản hồi HTTP 403 Forbidden trong đó không có nội dung nào được trả về) - nhưng với lợi ích bổ sung là thông báo cho crawler rằng có thể có mối quan hệ trong tương lai.
Việc xác định liệu nội dung có yêu cầu thanh toán hay không có thể xảy ra thông qua hai quy trình: Phản ứng (discovery-first) và Chủ động (intent-first). Trong quy trình phản ứng, nếu crawler yêu cầu một URL có trả phí, Cloudflare sẽ trả về phản hồi HTTP 402 Payment Required, kèm theo header crawler-price. Điều này báo hiệu rằng cần thanh toán cho tài nguyên được yêu cầu. Crawler sau đó có thể quyết định thử lại yêu cầu, lần này bao gồm header crawler-exact-price để chỉ ra sự đồng ý thanh toán mức giá đã cấu hình.
Trong phương pháp chủ động, crawler có thể bao gồm trước header crawler-max-price trong yêu cầu ban đầu. Nếu giá được cấu hình cho một tài nguyên bằng hoặc dưới giới hạn được chỉ định này, yêu cầu sẽ tiếp tục và nội dung được phục vụ với phản hồi HTTP 200 OK thành công, xác nhận việc tính phí.
Lợi ích cho chủ sở hữu website và nhà xuất bản
Tính năng pay per crawl mang lại những lợi ích đáng kể cho các chủ sở hữu website và nhà xuất bản nội dung. Trước hết, nó giải quyết được vấn đề cơ bản mà nhiều nhà sáng tạo nội dung đang đối mặt: nếu bạn không bồi thường cho các nhà sáng tạo theo cách này hay cách khác, thì họ sẽ ngừng sáng tạo, như CEO Matthew Prince của Cloudflare đã nói.
Hệ thống này cho phép các nhà xuất bản có ba tùy chọn rõ ràng thay vì chỉ có lựa chọn nhị phân trước đây. Họ có thể cho phép truy cập miễn phí, tính phí theo mức giá đã định, hoặc chặn hoàn toàn. Sự linh hoạt này đặc biệt hữu ích vì các nhà xuất bản vẫn giữ được sự linh hoạt để bỏ qua phí cho các crawler cụ thể khi cần thiết.
Đối với các tổ chức báo chí và nhà xuất bản lớn, tính năng này mở ra cơ hội tạo ra một nguồn thu nhập mới từ nội dung mà họ đã đầu tư nhiều thời gian và công sức để tạo ra. Thay vì phải đàm phán từng thỏa thuận riêng lẻ với các công ty AI, họ có thể sử dụng một hệ thống tự động để kiếm tiền từ việc truy cập nội dung.
Hơn một triệu khách hàng đã chọn tùy chọn chặn AI crawler kể từ khi Cloudflare giới thiệu tính năng này vào tháng 9 năm 2024. Con số này cho thấy mức độ quan tâm cao từ phía các chủ sở hữu website về việc kiểm soát cách AI truy cập nội dung của họ.
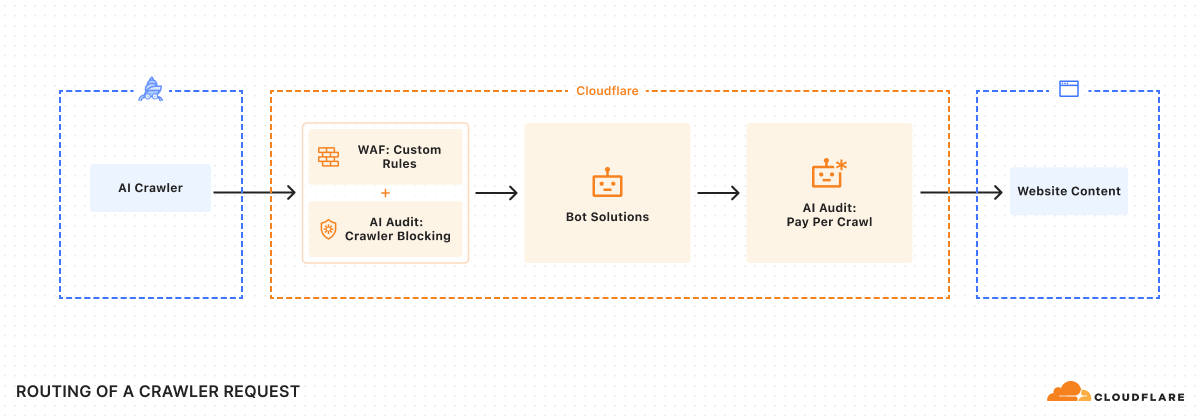
Hệ thống này cũng được thiết kế để tích hợp với tư thế bảo mật hiện có của mỗi nhà xuất bản. Cloudflare thực thi các quyết định Cho phép hoặc Tính phí thông qua một công cụ quy tắc chỉ hoạt động sau khi các chính sách WAF hiện có và các tính năng quản lý bot hoặc chặn bot đã được áp dụng.
Một lợi ích khác là khả năng theo dõi và phân tích. Các sự kiện thanh toán được ghi lại mỗi khi crawler thực hiện yêu cầu được xác thực với ý định thanh toán và nhận được phản hồi HTTP cấp 200 với header crawler-charged. Cloudflare sau đó tổng hợp tất cả các sự kiện, tính phí crawler và phân phối thu nhập cho nhà xuất bản.
Tác động đến ngành công nghiệp trí tuệ nhân tạo
Sự ra mắt của tính năng pay per crawl có thể tạo ra những thay đổi sâu sắc trong cách các công ty trí tuệ nhân tạo tiếp cận và sử dụng dữ liệu web. Điều này có thể dẫn đến sự thay đổi cơ bản trong mô hình kinh doanh của nhiều công ty AI, đặc biệt là những công ty phụ thuộc nhiều vào việc thu thập dữ liệu miễn phí từ web để huấn luyện và cải thiện các mô hình của họ.
Đối với các công ty AI lớn như OpenAI, Google, hoặc Anthropic, việc phải trả phí cho việc thu thập dữ liệu có thể tăng đáng kể chi phí hoạt động. Tuy nhiên, điều này cũng có thể tạo ra một thị trường công bằng hơn, nơi chất lượng và giá trị của dữ liệu được đánh giá đúng mức thay vì được coi là tài nguyên miễn phí.
Hệ thống này cũng có thể khuyến khích sự phát triển của các tiêu chuẩn mới trong ngành. Cloudflare đã phải giải quyết một thách thức kỹ thuật cực kỳ quan trọng: đảm bảo rằng họ có thể tính phí một crawler cụ thể, nhưng ngăn chặn bất kỳ ai giả mạo crawler đó. Giải pháp của họ sử dụng đề xuất Web Bot Auth, đòi hỏi các crawler phải có cặp khóa Ed25519 và sử dụng HTTP Message Signatures với mỗi yêu cầu.
Điều này có nghĩa là các công ty AI sẽ cần đầu tư vào cơ sở hạ tầng xác thực và bảo mật mạnh mẽ hơn để có thể tham gia vào hệ sinh thái mới này. Các crawler sẽ cần đăng ký với Cloudflare, cung cấp URL của thư mục khóa và thông tin user agent, cũng như cấu hình crawler của họ để sử dụng chữ ký tin nhắn HTTP với mỗi yêu cầu.
Về mặt tích cực, hệ thống này có thể dẫn đến chất lượng dữ liệu tốt hơn cho các mô hình AI. Khi các nhà sáng tạo nội dung được bồi thường công bằng cho công việc của họ, họ có thể có động lực tạo ra nội dung chất lượng cao hơn và đa dạng hơn. Điều này cuối cùng có thể cải thiện chất lượng của các mô hình AI được huấn luyện trên dữ liệu này.
Hướng dẫn thiết lập và sử dụng tính năng
Để sử dụng tính năng pay per crawl, cả nhà khai thác crawler và chủ sở hữu nội dung đều cần cấu hình chi tiết thanh toán trong tài khoản Cloudflare của họ. Quá trình này được thiết kế để đơn giản nhưng vẫn đảm bảo tính bảo mật và xác thực cao.
Đối với các chủ sở hữu website muốn tham gia chương trình, mỗi khách hàng tên miền mới đăng ký với Cloudflare để quản lý lưu lượng truy cập website của họ giờ đây sẽ được hỏi liệu họ có muốn cho phép AI crawler hay chặn chúng hoàn toàn. Điều này cho thấy Cloudflare đang tích hợp tính năng này vào quy trình đăng ký tiêu chuẩn của họ.
Quá trình thiết lập cho các crawler phức tạp hơn một chút. Crawler cần thực hiện một số bước kỹ thuật: tạo cặp khóa Ed25519 và làm cho khóa công khai được định dạng JWK có sẵn trong thư mục được lưu trữ, đăng ký với Cloudflare để cung cấp URL của thư mục khóa và thông tin user agent, và cấu hình crawler để sử dụng HTTP Message Signatures với mỗi yêu cầu.
Khi đăng ký được chấp nhận, các yêu cầu crawler phải luôn bao gồm các header signature-agent, signature-input và signature để xác định crawler và khám phá các tài nguyên trả phí. Điều này đảm bảo rằng chỉ những crawler được xác thực mới có thể tham gia vào hệ thống thanh toán.
Hệ thống cũng cho phép định giá động và linh hoạt. Mặc dù hiện tại các nhà xuất bản có thể định nghĩa một mức giá cố định trên toàn bộ trang web của họ, Cloudflare đã chỉ ra rằng họ dự kiến hệ thống sẽ phát triển đáng kể. Họ tin rằng nhiều loại tương tác và thị trường khác nhau có thể và nên phát triển đồng thời.
Việc thanh toán được xử lý tự động thông qua hệ thống của Cloudflare. Các sự kiện thanh toán được ghi lại, Cloudflare tổng hợp tất cả các sự kiện, tính phí cho crawler và phân phối thu nhập cho nhà xuất bản. Điều này loại bỏ nhu cầu về các thỏa thuận thanh toán phức tạp giữa từng cặp crawler-publisher.
Thách thức và cơ hội trong tương lai
Hệ thống pay per crawl của Cloudflare mở ra nhiều cơ hội thú vị nhưng cũng đặt ra không ít thách thức. Một trong những cơ hội lớn nhất nằm trong thế giới agentic - các tác nhân AI tự động. Cloudflare tưởng tượng một tương lai nơi các tác nhân thông minh có thể đàm phán truy cập vào tài nguyên kỹ thuật số một cách lập trình.
Họ mô tả một tình huống trong đó bạn có thể yêu cầu chương trình nghiên cứu sâu yêu thích của mình giúp bạn tổng hợp nghiên cứu ung thư mới nhất hoặc một bản tóm tắt pháp lý, hoặc chỉ giúp bạn tìm nhà hàng tốt nhất ở Soho - và sau đó cung cấp cho tác nhân đó một ngân sách để chi tiêu nhằm có được nội dung tốt nhất và phù hợp nhất.
Tuy nhiên, có một số thách thức đáng kể cần được giải quyết. Một mối quan tâm được đặt ra trên Hacker News là về tác động có thể có đối với Common Crawl project. Common Crawl chạy một lần và cung cấp dữ liệu ở các định dạng tiêu chuẩn ngành như WARC cho các người tiêu dùng khác, thay vì hàng chục công ty viết và chạy các crawler được thiết kế kém.
Có những lo ngại về việc Cloudflare có thể trở thành "người gác cổng" cho nội dung web. Điều này có thể dẫn đến một thế giới nơi phần lớn các website chỉ có thể truy cập thông qua các dịch vụ của Cloudflare, có thể tạo ra sự phụ thuộc không mong muốn vào một công ty duy nhất.
Về mặt kỹ thuật, hệ thống này đặt ra câu hỏi về khả năng mở rộng và công bằng. Các công ty AI nhỏ hơn có thể gặp khó khăn trong việc cạnh tranh với các gã khổng lồ công nghệ có nhiều tài chính hơn để trả cho việc truy cập dữ liệu chất lượng cao. Điều này có thể dẫn đến sự tập trung quyền lực hơn nữa trong ngành AI.
Mặt khác, hệ thống này có thể khuyến khích sự đổi mới trong cách các công ty AI tiếp cận việc thu thập và sử dụng dữ liệu. Thay vì dựa vào việc thu thập dữ liệu quy mô lớn một cách mù quáng, họ có thể phải trở nên có chọn lọc và hiệu quả hơn, tập trung vào dữ liệu chất lượng cao và có liên quan.
Cloudflare cũng đã chỉ ra rằng họ mong đợi pay per crawl sẽ phát triển đáng kể. Họ đặt ra nhiều câu hỏi thú vị về tương lai: làm thế nào để một nhà xuất bản hoặc tổ chức tin tức có thể tính phí khác nhau cho các đường dẫn hoặc loại nội dung khác nhau? Làm thế nào để giới thiệu định giá động dựa không chỉ trên nhu cầu mà còn trên số lượng người dùng mà ứng dụng AI của bạn có? Làm thế nào để giới thiệu các giấy phép chi tiết ở quy mô internet, dù là để huấn luyện, suy luận, tìm kiếm hay một cái gì đó hoàn toàn mới?
Kết luận
Sự ra mắt của tính năng pay per crawl của Cloudflare đánh dấu một bước ngoặt quan trọng trong mối quan hệ giữa các nhà sáng tạo nội dung và ngành công nghiệp trí tuệ nhân tạo. Thay vì việc thu thập dữ liệu một chiều mà không có sự đồng ý hoặc bồi thường, hệ thống này tạo ra một thị trường công bằng hơn nơi giá trị của nội dung được công nhận và bồi thường thỏa đáng.
Tính năng pay per crawl bắt đầu một sự chuyển đổi kỹ thuật trong cách nội dung được kiểm soát trực tuyến. Bằng cách cung cấp cho các nhà sáng tạo một cơ chế lập trình mạnh mẽ để định giá và kiểm soát tài sản kỹ thuật số của họ, Cloudflare trao quyền cho họ tiếp tục tạo ra nội dung phong phú và đa dạng làm cho Internet trở nên vô giá.
Mặc dù hệ thống này vẫn còn ở giai đoạn rất sớm và cần được thử nghiệm thêm, nó đã mở ra những khả năng thú vị cho tương lai. Với sự phát triển của các tác nhân AI và nhu cầu ngày càng tăng về dữ liệu chất lượng cao, hệ thống như pay per crawl có thể trở thành tiêu chuẩn trong ngành.
Thành công của tính năng này sẽ phụ thuộc vào việc cân bằng các lợi ích của tất cả các bên liên quan: các nhà sáng tạo nội dung muốn được bồi thường công bằng, các công ty AI cần truy cập dữ liệu chất lượng, và người dùng cuối cùng muốn có các sản phẩm AI tốt hơn. Nếu được thực hiện đúng cách, đây có thể là bước đầu tiên trong việc tạo ra một hệ sinh thái AI bền vững và công bằng cho tất cả mọi người.
Tài liệu tham khảo
- Cloudflare Blog. (2025, July 1). Introducing pay per crawl: enabling content owners to charge AI crawlers for access. https://blog.cloudflare.com/introducing-pay-per-crawl/
- TechCrunch. (2025, July 1). Cloudflare launches a marketplace that lets websites charge AI bots for scraping. https://techcrunch.com/2025/07/01/cloudflare-launches-a-marketplace-that-lets-websites-charge-ai-bots-for-scraping/
- Cloudflare Press Release. (2025). Cloudflare Just Changed How AI Crawlers Scrape the Internet-at-Large; Permission-Based Approach Makes Way for A New Business Model. https://www.cloudflare.com/press-releases/2025/cloudflare-just-changed-how-ai-crawlers-scrape-the-internet-at-large/
- Engadget. (2025, July 1). Cloudflare experiment will block AI bot scrapers unless they pay a fee. https://www.engadget.com/ai/cloudflare-experiment-will-block-ai-bot-scrapers-unless-they-pay-a-fee-121523327.html
- Hacker News Discussion. Cloudflare's new marketplace lets websites charge AI bots for scraping. https://news.ycombinator.com/item?id=41625903
- TechCrunch. (2024, September 23). Cloudflare's new marketplace will let websites charge AI bots for scraping. https://techcrunch.com/2024/09/23/cloudflares-new-marketplace-will-let-websites-charge-ai-bots-for-scraping/
- Cloudflare Blog. (2024, October 9). Declare your AIndependence: block AI bots, scrapers and crawlers with a single click. https://blog.cloudflare.com/declaring-your-aindependence-block-ai-bots-scrapers-and-crawlers-with-a-single-click/
- Maginative. (2024, September 23). Cloudflare to Launch Marketplace Allowing Websites to Charge AI Models for Content Scraping. https://www.maginative.com/article/cloudflare-to-launch-marketplace-allowing-websites-to-charge-ai-models-for-content-scraping/