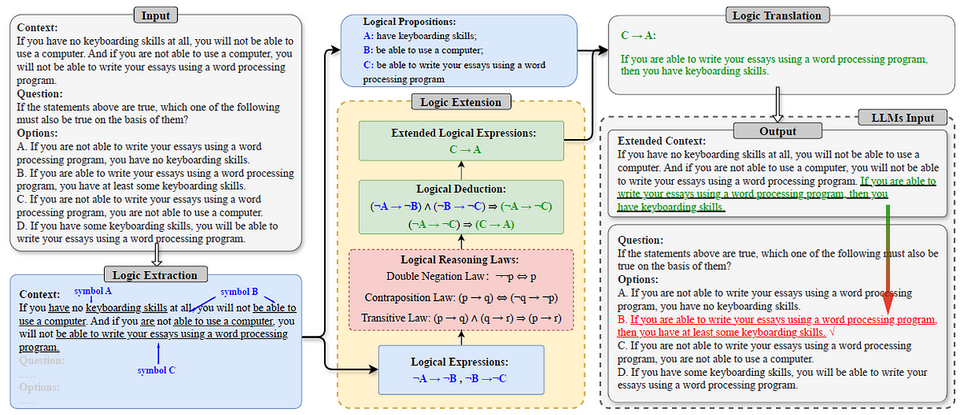
Các Tham Số LLM (Large Language Model) và Cách Sử Dụng Hiệu Quả
Khám phá các tham số quan trọng của mô hình ngôn ngữ lớn (LLM) như Temperature, Top-p, Top-k và cách điều chỉnh chúng để tối ưu hóa kết quả cho nhiều mục đích khác nhau.
Giới Thiệu về Tham Số LLM
Các mô hình ngôn ngữ lớn (LLM) như GPT, Claude, Llama và Gemini đã trở thành công cụ mạnh mẽ trong việc tạo ra nội dung, hỗ trợ công việc và giải quyết nhiều vấn đề khác nhau. Tuy nhiên, để khai thác tối đa tiềm năng của các mô hình này, việc hiểu và điều chỉnh các tham số (parameters) là vô cùng quan trọng. Bài viết này sẽ giúp bạn hiểu rõ về các tham số chính của LLM và cách sử dụng chúng hiệu quả.
Các Tham Số Quan Trọng của LLM
1. Temperature (Nhiệt độ)
Temperature là một trong những tham số cơ bản và quan trọng nhất khi làm việc với LLM. Tham số này kiểm soát mức độ ngẫu nhiên trong đầu ra của mô hình.
Giá trị và ý nghĩa:
- Thang giá trị: Thường từ 0 đến 2, với 1 là giá trị mặc định
- Temperature thấp (0 - 0.3):
- Tạo ra kết quả có tính xác định cao
- Mô hình sẽ chọn các từ có xác suất cao nhất
- Phù hợp cho các tác vụ yêu cầu độ chính xác cao như trả lời câu hỏi thực tế, lập trình, tóm tắt
- Temperature trung bình (0.4 - 0.7):
- Cân bằng giữa tính nhất quán và sáng tạo
- Phù hợp cho nhiều ứng dụng thông thường
- Temperature cao (0.8 - 2.0):
- Tạo ra kết quả đa dạng, sáng tạo và đôi khi bất ngờ
- Phù hợp cho việc sáng tác văn học, thơ ca, kịch bản, brainstorming ý tưởng
Ví dụ thực tế:
# Sử dụng temperature thấp cho câu trả lời chính xác
response = model.generate(prompt="Giải thích quy trình quang hợp", temperature=0.2)
# Sử dụng temperature cao cho sáng tạo
response = model.generate(prompt="Viết một câu chuyện ngắn về robot", temperature=1.2)
2. Top-p (Nucleus Sampling)
Top-p, còn được gọi là nucleus sampling, là một phương pháp lấy mẫu kiểm soát sự đa dạng của đầu ra bằng cách chỉ xem xét các token có tổng xác suất cộng dồn đạt đến ngưỡng p.
Giá trị và ý nghĩa:
- Thang giá trị: Từ 0 đến 1, thường sử dụng từ 0.9 đến 0.95
- Top-p thấp (< 0.5):
- Giới hạn lựa chọn từ vựng, tạo ra nội dung an toàn và dễ đoán
- Phù hợp cho các tác vụ cần độ chính xác cao
- Top-p cao (> 0.9):
- Cho phép mô hình xem xét nhiều khả năng hơn
- Tạo ra nội dung đa dạng, phong phú
Cách hoạt động:
- Mô hình sắp xếp các token tiếp theo theo xác suất từ cao đến thấp
- Tính tổng xác suất cộng dồn
- Chỉ xem xét các token nằm trong ngưỡng p (ví dụ: top-p = 0.9 sẽ chỉ xem xét các token chiếm 90% xác suất cộng dồn)
Ví dụ thực tế:
# Sử dụng top-p thấp cho câu trả lời nhất quán
response = model.generate(prompt="Liệt kê các bước giải phương trình bậc hai", top_p=0.4)
# Sử dụng top-p cao cho nội dung sáng tạo
response = model.generate(prompt="Viết một bài thơ về mùa thu", top_p=0.95)
3. Top-k
Top-k là một phương pháp lấy mẫu giới hạn số lượng token tiếp theo mà mô hình xem xét, chỉ chọn k token có xác suất cao nhất.
Giá trị và ý nghĩa:
- Thang giá trị: Số nguyên dương, thường từ 10 đến 100
- Top-k thấp (10-20):
- Giới hạn nghiêm ngặt các lựa chọn
- Tạo ra nội dung an toàn, ít sai sót
- Top-k cao (50-100):
- Cho phép nhiều lựa chọn hơn
- Tạo ra nội dung đa dạng hơn
Cách hoạt động:
- Mô hình xếp hạng tất cả các token tiếp theo theo xác suất
- Chỉ giữ lại k token có xác suất cao nhất
- Áp dụng sampling (có thể kết hợp với temperature) trên tập k token này
Ví dụ thực tế:
# Sử dụng top-k thấp cho câu trả lời chính xác
response = model.generate(prompt="Giải thích nguyên lý hoạt động của động cơ điện", top_k=20)
# Sử dụng top-k cao cho nội dung đa dạng
response = model.generate(prompt="Đề xuất các ý tưởng marketing", top_k=80)
4. Max Tokens (Số token tối đa)
Tham số này xác định độ dài tối đa của đầu ra mà mô hình sẽ tạo ra.
Giá trị và ý nghĩa:
- Thang giá trị: Số nguyên dương, phụ thuộc vào giới hạn của mô hình
- Giá trị thấp: Tạo ra câu trả lời ngắn gọn, súc tích
- Giá trị cao: Cho phép câu trả lời dài, chi tiết
Ví dụ thực tế:
# Tạo câu trả lời ngắn gọn
response = model.generate(prompt="Tóm tắt cuốn sách Đắc Nhân Tâm", max_tokens=100)
# Tạo câu trả lời chi tiết
response = model.generate(prompt="Phân tích tác phẩm Truyện Kiều", max_tokens=2000)
5. Presence Penalty và Frequency Penalty
Hai tham số này giúp kiểm soát sự lặp lại trong văn bản được tạo ra.
Presence Penalty:
- Áp dụng hình phạt cho các token đã xuất hiện ít nhất một lần
- Khuyến khích mô hình đề cập đến các chủ đề mới
Frequency Penalty:
- Áp dụng hình phạt dựa trên tần suất xuất hiện của token
- Token xuất hiện càng nhiều, hình phạt càng cao
- Giúp giảm sự lặp lại từ ngữ và ý tưởng
Giá trị và ý nghĩa:
- Thang giá trị: Thường từ -2.0 đến 2.0
- Giá trị âm: Khuyến khích lặp lại (hiếm khi sử dụng)
- Giá trị 0: Không áp dụng hình phạt
- Giá trị dương: Giảm sự lặp lại, tăng tính đa dạng
Ví dụ thực tế:
# Giảm sự lặp lại trong bài viết dài
response = model.generate(
prompt="Viết một bài luận về biến đổi khí hậu",
presence_penalty=0.6,
frequency_penalty=0.8
)
Cách Kết Hợp Các Tham Số LLM
Việc kết hợp các tham số khác nhau có thể tạo ra kết quả tối ưu cho từng loại tác vụ cụ thể. Dưới đây là một số cách kết hợp phổ biến:
1. Cho Nội Dung Thông Tin Chính Xác
Temperature: 0.1-0.3
Top-p: 0.1-0.5
Top-k: 10-30
Presence Penalty: 0.0-0.2
Frequency Penalty: 0.0-0.2
Cấu hình này phù hợp cho:
- Trả lời câu hỏi thực tế
- Tóm tắt tài liệu
- Lập trình và debug
- Giải thích khái niệm khoa học
2. Cho Nội Dung Cân Bằng
Temperature: 0.4-0.7
Top-p: 0.7-0.8
Top-k: 40-60
Presence Penalty: 0.3-0.5
Frequency Penalty: 0.3-0.5
Cấu hình này phù hợp cho:
- Viết email chuyên nghiệp
- Tạo nội dung blog
- Trả lời câu hỏi tư vấn
- Viết báo cáo
3. Cho Nội Dung Sáng Tạo
Temperature: 0.8-1.2
Top-p: 0.9-1.0
Top-k: 80-100
Presence Penalty: 0.5-0.8
Frequency Penalty: 0.5-0.8
Cấu hình này phù hợp cho:
- Sáng tác thơ, truyện ngắn
- Brainstorming ý tưởng
- Viết kịch bản
- Tạo nội dung hài hước
Hướng Dẫn Thực Hành: Điều Chỉnh Tham Số Theo Mục Đích
1. Khi Cần Thông Tin Chính Xác
# Ví dụ với OpenAI API
import openai
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Giải thích chi tiết về hiệu ứng nhà kính"}
],
temperature=0.2,
top_p=0.3,
max_tokens=500,
frequency_penalty=0.0,
presence_penalty=0.0
)
2. Khi Cần Sáng Tạo Nội Dung
# Ví dụ với OpenAI API
import openai
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Viết một câu chuyện ngắn về một robot có cảm xúc"}
],
temperature=1.0,
top_p=0.95,
max_tokens=1000,
frequency_penalty=0.7,
presence_penalty=0.6
)
3. Khi Cần Tạo Nội Dung Chuyên Nghiệp
# Ví dụ với OpenAI API
import openai
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Viết một email chuyên nghiệp gửi cho khách hàng về sản phẩm mới"}
],
temperature=0.5,
top_p=0.8,
max_tokens=800,
frequency_penalty=0.4,
presence_penalty=0.3
)
Các Lỗi Thường Gặp và Cách Khắc Phục
1. Nội Dung Quá Lặp Lại
Nguyên nhân:
- Temperature quá thấp
- Frequency penalty và presence penalty quá thấp
Cách khắc phục:
- Tăng temperature lên 0.5-0.7
- Tăng frequency penalty và presence penalty lên 0.5-0.8
2. Nội Dung Thiếu Nhất Quán, Lạc Đề
Nguyên nhân:
- Temperature quá cao
- Top-p quá cao
Cách khắc phục:
- Giảm temperature xuống 0.2-0.4
- Giảm top-p xuống 0.5-0.7
3. Nội Dung Quá Ngắn
Nguyên nhân:
- Max tokens quá thấp
- Prompt không đủ chi tiết
Cách khắc phục:
- Tăng max tokens
- Cung cấp prompt chi tiết hơn với yêu cầu cụ thể về độ dài
4. Nội Dung Quá Dài, Lan Man
Nguyên nhân:
- Max tokens quá cao
- Presence penalty quá cao
Cách khắc phục:
- Giảm max tokens
- Điều chỉnh presence penalty xuống 0.2-0.4
- Yêu cầu cụ thể về độ ngắn gọn trong prompt
Tối Ưu Hóa Tham Số Theo Loại Ứng Dụng
1. Chatbot Hỗ Trợ Khách Hàng
Temperature: 0.3-0.5
Top-p: 0.7-0.8
Max Tokens: 150-300
Frequency Penalty: 0.3-0.5
Presence Penalty: 0.3-0.5
2. Hệ Thống Hỏi Đáp (Q&A)
Temperature: 0.1-0.3
Top-p: 0.3-0.5
Max Tokens: 200-500
Frequency Penalty: 0.2-0.4
Presence Penalty: 0.2-0.4
3. Công Cụ Sáng Tạo Nội Dung
Temperature: 0.7-1.0
Top-p: 0.9-1.0
Max Tokens: 500-2000
Frequency Penalty: 0.5-0.8
Presence Penalty: 0.5-0.8
4. Công Cụ Tóm Tắt
Temperature: 0.2-0.4
Top-p: 0.5-0.7
Max Tokens: Phụ thuộc vào độ dài mong muốn
Frequency Penalty: 0.4-0.6
Presence Penalty: 0.4-0.6
Kết Luận
Việc hiểu và điều chỉnh các tham số LLM là yếu tố quan trọng để tối ưu hóa kết quả từ các mô hình ngôn ngữ lớn. Không có một cấu hình "hoàn hảo" cho mọi tình huống, vì vậy việc thử nghiệm và điều chỉnh dựa trên nhu cầu cụ thể là cần thiết.
Hãy nhớ rằng:
- Temperature kiểm soát mức độ ngẫu nhiên
- Top-p và Top-k kiểm soát phạm vi lựa chọn token
- Frequency và Presence penalty giúp giảm sự lặp lại
- Max tokens xác định độ dài đầu ra
Bằng cách kết hợp các tham số này một cách thông minh, bạn có thể tạo ra nội dung phù hợp với mục đích cụ thể, từ thông tin chính xác đến nội dung sáng tạo.
Tài Liệu Tham Khảo
- Huyen Chip. (2024). "Generation configurations: temperature, top-k, top-p, and test time compute". https://huyenchip.com/2024/01/16/sampling.html
- phData. (2023). "How to Tune LLM Parameters for Top Performance: Understanding Temperature, Top K, and Top P". https://phdata.io/blog/how-to-tune-llm-parameters-for-top-performance-understanding-temperature-top-k-and-top-p
- OpenAI Developer Community. (2023). "Cheat Sheet: Mastering Temperature and Top_p in ChatGPT API". https://community.openai.com/t/cheat-sheet-mastering-temperature-and-top-p-in-chatgpt-api/172683
- Prompt Engineering Guide. "LLM Settings". https://promptingguide.ai/introduction/settings
- Got It Vietnam. (2023). "Tổng quan về Prompt Engineering". https://vn.got-it.ai/blog/tong-quan-ve-prompt-engineering
- Medium. (2023). "Beyond temperature: Tuning LLM output with top-k and top-p". https://medium.com/google-cloud/beyond-temperature-tuning-llm-output-with-top-k-and-top-p-24c2de5c3b16
- Adel Basli. (2023). "My Guide to Fine-Tuning Top_p and Temperature in LLMs". https://medium.com/@adelbasli/taming-the-wild-imagination-fine-tuning-top-p-and-temperature-in-llms-2e7dac30658d