Các loại Hallucination trong Mô hình Ngôn ngữ Lớn
Bài viết giải thích dễ hiểu về hiện tượng hallucination (ảo giác) trong các mô hình AI ngôn ngữ lớn, phân loại các dạng chính, nguyên nhân và cách phát hiện, giúp người dùng hiểu rõ hơn về thách thức quan trọng này khi sử dụng công nghệ AI hiện đại.
Giới thiệu
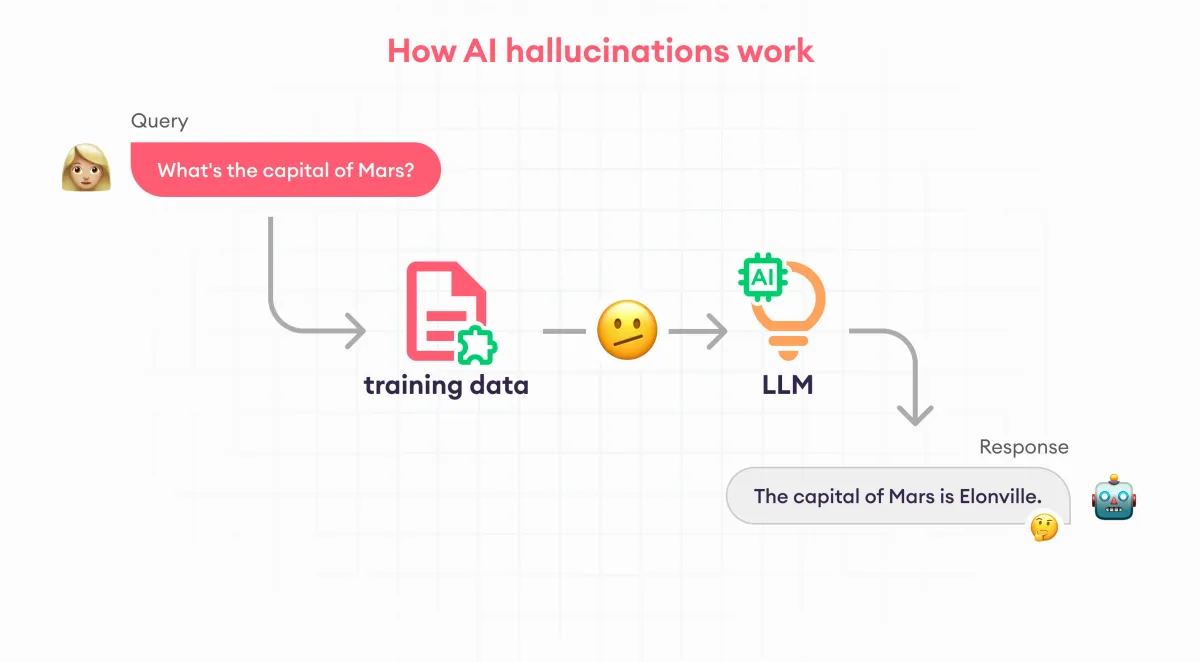
Mô hình ngôn ngữ lớn (Large Language Models - LLMs) như ChatGPT, Gemini hay Claude đã tạo ra bước tiến lớn trong công nghệ AI. Tuy nhiên, một vấn đề nghiêm trọng của các mô hình này là hiện tượng "hallucination" - khi AI tạo ra thông tin nghe có vẻ đúng nhưng thực tế lại sai hoặc bịa đặt.
Hiện tượng hallucination làm giảm độ tin cậy của AI và gây ra nhiều lo ngại khi sử dụng chúng trong các lĩnh vực quan trọng như y tế, luật pháp hay giáo dục. Bài viết này sẽ giải thích các loại hallucination chính trong LLM, nguyên nhân và cách phát hiện dựa trên các nghiên cứu khoa học mới nhất.
Hallucination trong LLM là gì?
Hallucination trong LLM là hiện tượng khi mô hình AI tạo ra nội dung nghe có vẻ đúng và đáng tin cậy nhưng thực tế lại không chính xác, bịa đặt, hoặc không thể kiểm chứng được. Đây giống như khi AI "mơ mộng" hoặc "tưởng tượng" ra thông tin không có thật.
Ví dụ thực tế: Trong một vụ kiện pháp lý ở New York (Mata v. Avianca), một luật sư đã sử dụng ChatGPT để nghiên cứu luật và đưa vào hồ sơ tòa án các trích dẫn và án lệ hoàn toàn không tồn tại do AI bịa ra.
Các loại Hallucination trong LLM
Dựa trên các nghiên cứu gần đây, hallucination trong LLM được chia thành các nhóm chính sau:
1. Intrinsic Hallucinations (Ảo giác Nội tại)
Đây là loại hallucination xảy ra khi LLM tạo ra thông tin mâu thuẫn trực tiếp với dữ liệu đầu vào hoặc ngữ cảnh được cung cấp. Loại này thường dễ phát hiện hơn vì có thể so sánh trực tiếp với thông tin đầu vào.
Ví dụ đơn giản: Bạn cung cấp đoạn văn có câu "Hà Nội là thủ đô của Việt Nam" nhưng AI tóm tắt lại và viết "Hồ Chí Minh là thủ đô của Việt Nam".
Intrinsic hallucinations có thể biểu hiện qua nhiều hình thức như mô tả sai mối quan hệ giữa các đối tượng (ví dụ: nói Elon Musk là CEO của Apple), mô tả sai trình tự thời gian (ví dụ: nói iPhone ra mắt trước BlackBerry), hoặc thêm/thay đổi các chi tiết không có trong nguồn (ví dụ: thêm các tính năng không tồn tại vào mô tả sản phẩm).
2. Extrinsic Hallucinations (Ảo giác Ngoại lai)
Extrinsic hallucinations xảy ra khi LLM tạo ra thông tin mới không có trong dữ liệu đầu vào và không thể kiểm chứng được từ ngữ cảnh đã cho. Loại này khó phát hiện hơn vì cần kiến thức bên ngoài để xác minh.
Ví dụ đơn giản: Khi bạn hỏi về một sự kiện lịch sử, AI có thể tạo ra các chi tiết, ngày tháng hoặc nhân vật không tồn tại trong thực tế. Theo nghiên cứu của Lilian Weng (2024), extrinsic hallucinations thường xảy ra khi mô hình "bịa đặt" thông tin mới dựa trên kiến thức đã học, nhưng không có cơ sở thực tế.
3. Amalgamated Hallucinations (Ảo giác Hỗn hợp)
Đây là loại hallucination kết hợp cả yếu tố nội tại và ngoại lai. AI trộn lẫn thông tin đúng từ nguồn với các thông tin bịa đặt để tạo ra nội dung có vẻ hợp lý nhưng không hoàn toàn chính xác.
Ví dụ đơn giản: Khi mô tả một sự kiện lịch sử, AI dùng đúng thời gian và địa điểm nhưng thêm vào các nhân vật hoặc chi tiết không tồn tại. Loại hallucination này đặc biệt nguy hiểm vì khó phát hiện do có pha trộn giữa thông tin đúng và sai.
4. Non-factual Hallucinations (Ảo giác Phi Sự thật)
Loại hallucination này liên quan đến việc AI tạo ra nội dung không phù hợp với kiến thức thực tế về thế giới, ngay cả khi không có thông tin cụ thể trong ngữ cảnh đầu vào.
Theo nghiên cứu của Sahoo và cộng sự (2024), non-factual hallucinations có nhiều biểu hiện khác nhau như đưa ra thông tin trái với sự thật (ví dụ: "Mặt trời quay quanh Trái đất"), đưa ra các suy đoán không có cơ sở (ví dụ: dự đoán chi tiết về sự kiện tương lai), đưa ra các lập luận không hợp lý hoặc mâu thuẫn, hoặc tạo ra nội dung không thể xảy ra trong thực tế.
Nguyên nhân của Hallucination trong LLM
Hiện tượng hallucination trong LLM xuất phát từ nhiều nguyên nhân phức tạp. Dữ liệu huấn luyện của LLM thường rất lớn nhưng không hoàn hảo, có thể chứa thông tin sai, thiếu sót hoặc mâu thuẫn, khiến AI học và tái tạo những thông tin sai lệch này. Khi AI cố gắng tổng quát hóa từ dữ liệu huấn luyện, nó có thể tạo ra các kết nối hoặc suy luận không chính xác giữa các khái niệm.
Một nguyên nhân quan trọng khác là LLM không có khả năng tự kiểm tra thông tin với thế giới thực. Chúng chỉ dựa vào mô hình xác suất đã học để tạo ra nội dung, không có cách nào để xác minh tính chính xác của thông tin. Ngoài ra, LLM được thiết kế để luôn tạo ra phản hồi, ngay cả khi không có đủ thông tin hoặc kiến thức về chủ đề, dẫn đến việc AI "bịa đặt" thông tin để hoàn thành nhiệm vụ.
Theo nghiên cứu của IBM (2024), hallucination trong AI cũng tương tự như hiện tượng con người đôi khi nhìn thấy hình dạng trong mây hoặc khuôn mặt trên mặt trăng. Trong trường hợp của AI, những diễn giải sai này xảy ra do nhiều yếu tố, bao gồm overfitting (quá khớp), độ phức tạp cao của mô hình, và sự thiên lệch hoặc không chính xác trong dữ liệu huấn luyện.
Cách Phát hiện Hallucination
Các nhà nghiên cứu đã phát triển nhiều phương pháp để phát hiện hallucination trong LLM. Một trong những phương pháp nổi bật là phát hiện dựa trên semantic entropy (entropy ngữ nghĩa), được công bố trên tạp chí Nature (2024). Phương pháp này phân tích sự biến thiên trong các câu trả lời của AI khi được hỏi cùng một câu hỏi nhiều lần với các cách diễn đạt khác nhau. Khi AI tạo ra hallucination, các câu trả lời thường có độ biến thiên cao hơn.
Phương pháp SelfCheckGPT, được phát triển bởi Manakul và cộng sự (2023), đánh giá tính nhất quán của nhiều câu trả lời được tạo ra cho cùng một câu hỏi. Nếu các câu trả lời không nhất quán, có khả năng cao là AI đang tạo ra hallucination. Tương tự, phương pháp metamorphic relations (quan hệ biến hình) biến đổi câu hỏi theo các cách khác nhau mà không làm thay đổi câu trả lời đúng, sau đó so sánh các phản hồi của AI để phát hiện sự không nhất quán.
Một phương pháp tiên tiến khác là token-level analysis (phân tích cấp token), phân tích độ tin cậy của từng token (đơn vị từ) trong câu trả lời của AI, giúp xác định chính xác phần nào của câu trả lời có khả năng là hallucination.
Cách Giảm thiểu Hallucination
Để giảm thiểu hallucination trong LLM, các nhà nghiên cứu đã phát triển nhiều phương pháp hiệu quả. Retrieval-Augmented Generation (RAG) là một trong những phương pháp phổ biến nhất, kết hợp khả năng tạo văn bản của LLM với hệ thống truy xuất thông tin, cho phép AI truy cập thông tin chính xác từ các nguồn đáng tin cậy trước khi tạo ra phản hồi.
Chain-of-Thought Prompting khuyến khích AI suy nghĩ từng bước trước khi đưa ra kết luận, giúp giảm thiểu các sai lầm logic và hallucination. RLHF (Reinforcement Learning from Human Feedback) sử dụng phản hồi của con người để tinh chỉnh mô hình, giúp giảm thiểu hallucination và cải thiện chất lượng phản hồi.
Các kỹ thuật tự đánh giá và kiểm tra thực tế yêu cầu AI tự đánh giá độ tin cậy của phản hồi và kiểm tra thông tin với các nguồn đáng tin cậy trước khi đưa ra câu trả lời cuối cùng. Theo nghiên cứu của Kili Technology (2024), việc sử dụng dữ liệu chất lượng cao, kỹ thuật prompt engineering nhận thức ngữ cảnh, và fine-tuning theo lĩnh vực cụ thể có thể giảm đáng kể sự xuất hiện của hallucination.
Thách thức và Hướng Nghiên cứu Tương lai
Mặc dù đã có nhiều tiến bộ trong việc phát hiện và giảm thiểu hallucination, vẫn còn nhiều thách thức cần giải quyết. Khi LLM được tích hợp với các phương thức khác như hình ảnh và video, việc phát hiện hallucination trở nên phức tạp hơn và đòi hỏi các phương pháp mới. Một thách thức lớn khác là làm thế nào để cân bằng giữa việc giảm thiểu hallucination và duy trì khả năng sáng tạo của AI.
Phát triển các phương pháp đánh giá khách quan và toàn diện về hallucination trong LLM vẫn là một lĩnh vực nghiên cứu đang phát triển. Nghiên cứu sâu hơn về cơ chế bên trong dẫn đến hallucination trong LLM sẽ giúp phát triển các phương pháp hiệu quả hơn để giảm thiểu vấn đề này.
Theo Andrej Karpathy, cựu Giám đốc cấp cao về AI tại Tesla, hiểu rõ "tâm lý học" của LLM là chìa khóa để giải quyết vấn đề hallucination. Ông cho rằng hallucination là hiệu ứng nhận thức nổi lên từ quy trình huấn luyện, và cần được nghiên cứu sâu hơn để phát triển các giải pháp hiệu quả.
Kết luận
Hiện tượng hallucination là một trong những thách thức lớn nhất đối với việc ứng dụng LLM trong các hệ thống thực tế đòi hỏi độ tin cậy cao. Việc hiểu rõ các loại hallucination, nguyên nhân và phương pháp phát hiện là bước quan trọng để phát triển các giải pháp hiệu quả nhằm giảm thiểu vấn đề này.
Các nghiên cứu trong tương lai cần tập trung vào việc phát triển các phương pháp mạnh mẽ hơn để phát hiện và giảm thiểu hallucination, đặc biệt trong các ứng dụng đa phương thức và các lĩnh vực đòi hỏi độ chính xác cao như y tế, luật pháp và giáo dục. Với sự phát triển nhanh chóng của công nghệ AI, việc giải quyết vấn đề hallucination sẽ là yếu tố quyết định để xây dựng các hệ thống AI đáng tin cậy và có trách nhiệm trong tương lai.
Tài liệu tham khảo
- Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y., Madotto, A., & Fung, P. (2023). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12), 1-38.
- Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, W., Jiang, X., Lyu, W., Zhu, Q., Ren, X., & Wang, H. (2023). A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. arXiv preprint arXiv:2311.05232.
- Manakul, P., Liusie, A., & Gales, M. J. F. (2023). SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models. Association for Computational Linguistics.
- Weng, L. (2024). Extrinsic Hallucinations in LLMs. Lil'Log. https://lilianweng.github.io/posts/2024-07-07-hallucination
- Sahoo, P., Veselovsky, P., Dhamala, J., Liang, P., & Paranjape, B. (2024). A Comprehensive Survey of Hallucination in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024.
- Karpathy, A. (2023). Deep Dive into LLMs like ChatGPT. YouTube.
- Lakera. (2024). The Beginner's Guide to Hallucinations in Large Language Models. https://lakera.ai/blog/guide-to-hallucinations-in-large-language-models
- Nature. (2024). Detecting hallucinations in large language models using semantic entropy. Nature, 630, 625–630.
- Iguazio. (2024). What are LLM Hallucinations? https://iguazio.com/glossary/llm-hallucination
- IBM. (2024). What Are AI Hallucinations? https://ibm.com/think/topics/ai-hallucinations